volatile在Java中的语义
对于volatile我们都比较熟悉,volatile在Java中有两种作用
- 保障字段在多线程之间的可见性
- 防止指令进行重排序(编译器层面和CPU层面,后面会说明)
下面我就来看一下jvm是如何实现这两种作用的
JVM对volatile的实现
volatile关键字只能用来修饰属性。对于属性有获取和设置两种操作,所以我们就从这两种操作入手分析一下JVM对volitile的处理。
上面的两种操作在字节码中对应着 getfield,getstatic和putfield,putfield这四种字节码。
我们去bytecodeinterpreter.cpp看一下对应的实现逻辑。(说明一下,JVM现在使用的是模板编译器的,但是字节码编译器可读性比较好,用来学习还是比较合适的)
我们找到上面几个字节码的执行位置
...
CASE(_getfield):
CASE(_getstatic):
{
...
if (cache->is_volatile()) {
if (support_IRIW_for_not_multiple_copy_atomic_cpu) {
OrderAccess::fence();
}
...
}
...
}
...
CASE(_putfield):
CASE(_putstatic):
{
...
if (cache->is_volatile()) {
...
OrderAccess::storeload();
}
...
}
可以看到,在访问对象字段的时候,会先判断它是不是volatile的,如果是的话,并且当前CPU平台支持多核核atomic操作的话(现代的绝大多数的CPU都支持),然后就调用OrderAccess::fence()。
在设置字段的时候,会使用OrderAccess::storeload();
这两个就是JVM提供的内存屏障。
JVM提供的内存屏障
JVM中,所有内存屏障的使用都由OrderAccess来提供。在OrderAccess.hpp中说明了JVM提供的几种内存屏障。
// Memory Access Ordering Model
//
// This interface is based on the JSR-133 Cookbook for Compiler Writers.
//
// In the following, the terms 'previous', 'subsequent', 'before',
// 'after', 'preceding' and 'succeeding' refer to program order. The
// terms 'down' and 'below' refer to forward load or store motion
// relative to program order, while 'up' and 'above' refer to backward
// motion.
//
// We define four primitive memory barrier operations.
//
// LoadLoad: Load1(s); LoadLoad; Load2
//
// Ensures that Load1 completes (obtains the value it loads from memory)
// before Load2 and any subsequent load operations. Loads before Load1
// may *not* float below Load2 and any subsequent load operations.
//
// StoreStore: Store1(s); StoreStore; Store2
//
// Ensures that Store1 completes (the effect on memory of Store1 is made
// visible to other processors) before Store2 and any subsequent store
// operations. Stores before Store1 may *not* float below Store2 and any
// subsequent store operations.
//
// LoadStore: Load1(s); LoadStore; Store2
//
// Ensures that Load1 completes before Store2 and any subsequent store
// operations. Loads before Load1 may *not* float below Store2 and any
// subsequent store operations.
//
// StoreLoad: Store1(s); StoreLoad; Load2
//
// Ensures that Store1 completes before Load2 and any subsequent load
// operations. Stores before Store1 may *not* float below Load2 and any
// subsequent load operations.
// 省略 acquire and release 部分内容
// Finally, we define a "fence" operation, as a bidirectional barrier.
// It guarantees that any memory access preceding the fence is not
// reordered w.r.t. any memory accesses subsequent to the fence in program
// order. This may be used to prevent sequences of loads from floating up
// above sequences of stores.
通过上面的注释我们知道,JVM根据JSR-133 Cook Book定义了4种基本的内存屏障操作,并由下面的几种作用。
| 内存屏障 | 使用方法 | 作用 |
|---|---|---|
| LoadLoad | Load1 LoadLoad Load2 | 确保Load1一定是在 Load2以及其后的指令之前完成 |
| StoreStore | Store1 StoreStore Store2 | 确保 Store1 一定是在 Store2 以及其后的指令之前完成 (同时,Store1的写入数据会立即被其他 CPU看到 |
| LoadStore | Load1 LoadStore Store2 | 确保 Load1 一定是在 Store2 以及其后的指令之前完成 |
| StoreLoad | Store1 StoreLoad Load2 | 确保 Store1 一定在 Load2 以及其后的指令之前完成 |
我们看到,在常见的4中基本内存屏障之后,还单独定义了fence操作,fence操作的功能可以说涵盖了上面的4中基本屏障。它可以保证fence前的任何操作op1都在op2之前完成。
JVM为每种屏障类型都定义了一个单独的方法,带代码中如果需要某种屏障可能直接调用。
static void loadload();
static void storestore();
static void loadstore();
static void storeload();
static void acquire();
static void release();
static void fence();
volatile和硬件的关系
volatile在上面提到的两个功能,都是通过JVM定义的内存屏障来实现的。
而JVM定义的内存屏障可以理解是一个规范,它要求不管在什么平台上都要有同样的效
果。但是最终还是要依靠硬件来实现。所以们可以看到,在JVM中对于各种硬件平台都有对应的内存屏障实现。
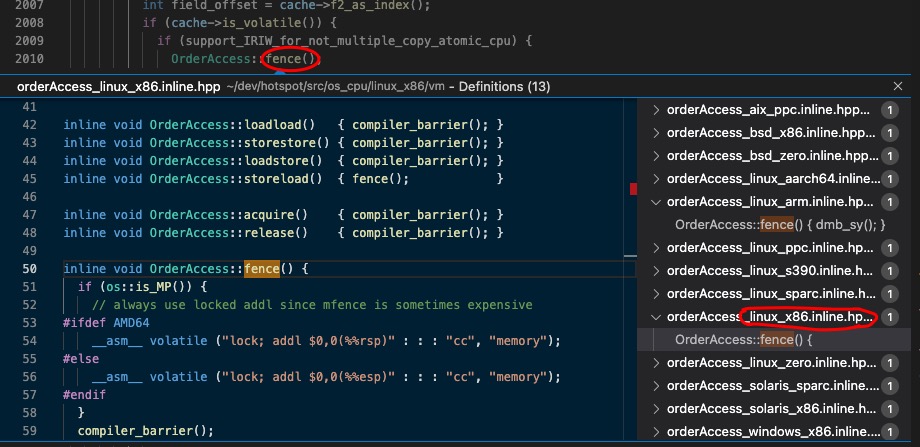
因为我们在服务器领域还是使用Linux比较多,而且大部分使用的是Intel的CPU,所以下面我们先关注一下linux_x86的实现
linux_x86内存屏障实现
static inline void compiler_barrier() {
__asm__ volatile ("" : : : "memory");
}
inline void OrderAccess::loadload() { compiler_barrier(); }
inline void OrderAccess::storestore() { compiler_barrier(); }
inline void OrderAccess::loadstore() { compiler_barrier(); }
inline void OrderAccess::storeload() { fence(); }
inline void OrderAccess::acquire() { compiler_barrier(); }
inline void OrderAccess::release() { compiler_barrier(); }
inline void OrderAccess::fence() {
if (os::is_MP()) {
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
}
compiler_barrier();
}
fence()和storeload()方法,都其实最终调用的都是fence()方法。其他的都是调用的compiler_barrier()方法。
然后这里两个方法里面都是使用的内嵌汇编指令的方式,所以我们下来分析一下这个内嵌汇编指令的格式。
内嵌汇编指令
内嵌汇编指令的格式是
__asm__ __volatile__("Instruction List" : Output : Input : Clobber/Modify);
__asm__或asm用来声明一个内联汇编表达式,所以任何一个内联汇编表达式都是以它开头的,是必不可少的。__volatile__或volatile是可选的。如果用了它,表示防止编译器对代码块进行优化。- 而这里的优化是针对代码块而言的,使用嵌入式汇编的代码分成三块:
- 嵌入式汇编之前的代码块
- 嵌入式汇编代码块
- 嵌入式汇编之后的c代码块
- 所以使用了
volatile修饰的内嵌汇编的意思是,防止编译器对汇编代码块及前后的代码进行重排序等优化。
Instruction List是要执行的汇编指令序列。它可以是空的。Output和Input是汇编指令中的输入和输出,都可以为空,这里我们不做过多分析Clobber/Modify是寄存器/内存修改标示。通知GCC当前内联汇编语句可能会对某些寄存器或内存进行修改,希望GCC在编译时能够将这一点考虑进去,这会对GCC在编译的时候有一些影响,但具体是什么影响我们就不深究了。
了解了内嵌汇编代码的格式,我们再来看上面的两个方法。
compiler_barrier():__asm__ volatile ("" : : : "memory");
禁止编译器对汇编代码前后的代码块,进行重排序等优化,并且告诉编译器我修改了memory中的内容
fence():__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
禁止编译器对汇编代码前后的代码块,进行重排序等优化,并且执行 lock; addl $0,0(%%esp)这条汇编指令,并且告诉编译器我修改了memory中的内容
Lock前缀指令
通过上面我们已经知道,JVM通过使用带有volatile关键字的内嵌汇编的方便,解决了编译器重排序的问题。那么CPU级别的重排序,和内存间的可见性是怎么实现的呢,下面我们就要用到Lock指令了。
我们看到在fence()方法内嵌的汇编代码中,使用了lock前缀指令,那lock前缀指令在这里起到的是什么作用呢。
Lock前缀指令的作用
在Intel 用户开发手册中关于lock前缀有这样的描述。
8.1- LOCKED ATOMIC OPERATIONS
The processor uses three interdependent mechanisms for carrying out locked atomic operations:
• Guaranteed atomic operations
• Bus locking, using the LOCK# signal and the LOCK instruction prefix
• Cache coherency protocols that ensure that atomic operations can be carried out on cached data structures (cache lock); this mechanism is present in the Pentium 4, Intel Xeon, and P6 family processors
意思是,我们有3种方式可以实现CPU的原子操作
- 使用被保证的原子操作,比如读写1byte等
- 使用
lock指令作为指令前缀 - 使用缓存一致性协议
所以使用lock指令作为前缀,能够把它后面的一个或者几个操作’包装’为一个原子操作。不过你可能会想,那这么说来lock的作用和我们使用它的目前好像不大一样啊,可见性呢?重排序呢?别急我们继续看。
Lock前缀保证可见性
lock前缀指令的实现方法,在早期CPU和现代CPU中有很大不同,我们还是引用开发手册中的描述
8.1.2-Bus Locking
In the case of the Intel386, Intel486, and Pentium processors, explicitly locked instructions will result in the asser- tion of the LOCK# signal. It is the responsibility of the hardware designer to make the LOCK# signal available in system hardware to control memory accesses among processors.
For the P6 and more recent processor families, if the memory area being accessed is cached internally in the processor, the LOCK# signal is generally not asserted; instead, locking is only applied to the processor’s caches
意思是,在早期的CPU中,当使用lock前缀指令时候,会导致产生一个LOCK#信号,通过总线锁定对应的内存,其它 CPU 对内存的读写请求都会被阻塞,直到锁释放。
在后来的处理器的处理逻辑中,如果要操作的内存,已经cache到了处理器的缓存中,那么将不会产生LOCK#信号,则通过缓存一致性协议来完成原子性的保证。
8.1.4-Effects of a LOCK Operation on Internal Processor Caches
For the P6 and more recent processor families, if the area of memory being locked during a LOCK operation is cached in the processor that is performing the LOCK operation as write-back memory and is completely contained in a cache line, the processor may not assert the LOCK# signal on the bus. Instead, it will modify the memory location internally and allow it’s cache coherency mechanism to ensure that the operation is carried out atomically. This operation is called “cache locking.” The cache coherency mechanism automatically prevents two or more processors that have cached the same area of memory from simultaneously modifying data in that area.
意思是:在LOCK操作中被锁定的内存区域是缓存在执行LOCK操作的处理器中,作为回写存储器,并且完全包含在缓存行中。在一个缓存行中,处理器可能不会在总线上发出LOCK#信号。相反,它将在内部修改内存位置,并允许它的缓存一致性机制确保该操作是原子式进行的。这种操作被称为”高速缓存锁定”。缓存一致性机制会自动防止两个或更多的处理器在缓存同一区域的内存上同时修改该区域的数据。
显而易见,使用总线锁定的方式代价要大得多。不过目前在大多数情况下,我们在使用lock指令的时候,都是通过缓存一致性协议来保证的后面操作的原子性操作。但是有一些情况同样也会导致不能使用高速缓存锁定,而只能使用总线锁定,比如涉及到的数据跨越多个CacheLine,CPU不支持缓存锁定等。
- 在 Pentium 和早期的 IA-32 处理器中,lock 前缀会使处理器执行当前指令时产生一个 LOCK# 信号,会对总线进行锁定,其它 CPU 对内存的读写请求都会被阻塞,直到锁释放
- 后来的处理器,加锁操作是由高速缓存锁代替总线锁来处理。 因为锁总线的开销比较大,锁总线期间其他CPU没法访问内存。 这种场景多缓存的数据一致通过缓存一致性协议(MESI)来保证。
所以总结一下,当我们使用lock前缀指令的时候会发生这两件事
- 要操作的数据在缓存中,会导致其他CPU的缓存行失效
- 如果数据不再内存中,则会使用总线锁定,把内存中的数据读入或者写出到内存。同时也会导致其他CPU的缓存行失效。
所以使用lock前缀指令,会通过触发缓存一致性协议导致关联的缓存行失效,从而保证可见性。
可见性我们知道了,那么防止指令重排序的作用呢?我们继续在用户手册中寻找一下答案。
Lock前缀防止指令重排
8.2.5 Strengthening or Weakening the Memory-Ordering Model
The Intel 64 and IA-32 architectures provide several mechanisms for strengthening or weakening the memory- ordering model to handle special programming situations. These mechanisms include:
• The I/O instructions, locking instructions, the LOCK prefix, and serializing instructions force stronger ordering on the processor.
• The SFENCE instruction (introduced to the IA-32 architecture in the Pentium III processor) and the LFENCE and MFENCE instructions (introduced in the Pentium 4 processor) provide memory-ordering and serialization capabilities for specific types of memory operations.
… 省略部分
Synchronization mechanisms in multiple-processor systems may depend upon a strong memory-ordering model. Here, a program can use a locking instruction such as the XCHG instruction or the LOCK prefix to ensure that a read-modify-write operation on memory is carried out atomically. Locking operations typically operate like I/O operations in that they wait for all previous instructions to complete and for all buffered writes to drain to memory
意思是,Intel处理器提供了几种机制用来加强或者削弱内存排序。其中使用IO相关指令、锁定指令、LOCK前缀指令、序列化相关指令都能够强化 排序。(这里强化的意思是,更加按照指令流的顺序来执行,也就是减少处理器的重排序)
在程序中可以使用锁定指令,或者lock前缀指令来强化排序,它们会等待所有先前的指令完成,并等待所有缓冲的写操作耗尽到内存中。
所以我们看到,JVM通过内嵌lock前缀的汇编指令,保证了可见性和防止了内存重排序。
Lock前缀指令的其他应用
我们经常使用的CAS的底层,也是使用lock前缀实现的,使用lock指令保证了后面的操作的原子性。
为何x86只实现了storeload内存屏障
还有一点我们在上面的x86的实现中看到,只有fence()方法,和storeload()方法使用lock前缀指令,其他的几种都是只是实现了编译器级别的内存屏障,也就是只能防止编译器的指令重排序。这是为什么呢?
同样我们在操作手册中寻找一下答案,在操作手册的 8.2.3-Examples Illustrating the Memory-Ordering章节,说明x86处理器对store和load指令的重排序情况
- 8.2.3.2 Neither Loads Nor Stores Are Reordered with Like Operations
- 8.2.3.3 Stores Are Not Reordered With Earlier Loads
- 8.2.3.4 Loads May Be Reordered with Earlier Stores to Different Locations
意思是
- load指令和store指令,都不能喝同类型的指令之间发生重排序,也就是 load1,load2 和 store1,store2 是不会发生重排序的
- store指令和前面出现的load指令,不会重排序,也就是 load1,store2 不会发生重排序。
- load指令,和它前面出现的store指令之间可能会发生重排序。
看到这,我们能知道,x86的CPU,在不添加任何内存屏障的情况下,已经支持了loadload,storestore,loadstore屏障了。只有storeload这种需要单独添加内存屏障来保证不会重排序。
所以对于x86处理器原生支持的3种屏障,只需要保证编译器不会发生重排序即可。
所以说,volatile的实现和硬件平台关系非常密切。
|处理器| Load-Load |Load-Store| Store-Store| Store-Load| 数据依赖| |x86| N |N N Y N PowerPC Y Y Y Y N ia64 Y Y Y Y N
为何x86下JVM使用LOCK前缀实现内存屏障
在Intel的处理器平台下内存屏障分为两类:
- 本身是内存屏障,比如“lfence”,“sfence”和“mfence”汇编指令
- 本身不是内存屏障,但是被LOCK指令前缀修饰,其组合成为一个内存屏障。在X86指令体系中,其中一类内存屏障常使用“LOCK指令前缀加上一个空操作”方式实现,比如
lock addl $0x0,(%esp)
所以有一个疑问,为什么JVM选择使用lock前缀指令来实现内存屏障而不使用专门的内存屏障指令呢?
我在JVM的源码中搜索了一下mfence,搜索到了下面几段注释
macroAssembler_x86.cpp
// We have a classic Dekker-style idiom:
// ST m->_owner = 0 ; MEMBAR; LD m->_succ
// There are a number of ways to implement the barrier:
// (1) lock:andl &m->_owner, 0
// is fast, but mask doesn't currently support the "ANDL M,IMM32" form.
// LOCK: ANDL [ebx+Offset(_Owner)-2], 0
// Encodes as 81 31 OFF32 IMM32 or 83 63 OFF8 IMM8
// (2) If supported, an explicit MFENCE is appealing.
// In older IA32 processors MFENCE is slower than lock:add or xchg
// particularly if the write-buffer is full as might be the case if
// if stores closely precede the fence or fence-equivalent instruction.
// See https://blogs.oracle.com/dave/entry/instruction_selection_for_volatile_fences
// as the situation has changed with Nehalem and Shanghai.
// (3) In lieu of an explicit fence, use lock:addl to the top-of-stack
// The $lines underlying the top-of-stack should be in M-state.
// The locked add instruction is serializing, of course.
// (4) Use xchg, which is serializing
// mov boxReg, 0; xchgl boxReg, [tmpReg + Offset(_owner)-2] also works
// (5) ST m->_owner = 0 and then execute lock:orl &m->_succ, 0.
// The integer condition codes will tell us if succ was 0.
// Since _succ and _owner should reside in the same $line and
// we just stored into _owner, it's likely that the $line
// remains in M-state for the lock:orl.
//
// We currently use (3), although it's likely that switching to (2)
// is correct for the future.
orderAccess_linux_x86.inline.hpp
// always use locked addl since mfence is sometimes expensive
大概意思就是说,mfence目前有几个缺点
1.并不是所有cpu都支持这个指令。
2. 在最早前的CPU中性能比lock前缀差一些。
3. 有时mfence的性能损耗比较严重
所以基于以上考虑,目前还是使用lock前缀(我查看的jvm源码是jdk11的),但是未来很有可能改为使用mfence指令。
Instruction selection for volatile fences : MFENCE vs LOCK:ADD
缓存一致性协议
在上面我们不止一次的提到了缓存一致性协议,那么缓存一致性协议具体是什么样的呢?下面我们来简单的了解一下。
现在处理器处理能力上要远胜于主内存(DRAM),主内存执行一次内存读写操作,所需的时间可能足够处理器执行上百条的指令,为了弥补处理器与主内存处理能力之间的鸿沟,引入了高速缓(Cache),来保存一些CPU从内存读取的数据,下次用到该数据直接从缓存中获取即可,以加快读取速度,随着多核时代的到来,每块CPU都有多个内核,每个内核都有自己的缓存,这样就会出现同一个数据的副本就会存在于多个缓存中,在读写的时候就会出现数据 不一致的情况。
缓存行
数据在缓存中不是以独立的项来存储的,它不是一个单独的变量,也不是一个单独的指针,它在数据缓存中以缓存行存在的,也称缓存行为缓存条目。目前主流的CPU Cache的Cache Line大小通常是64字节,并且它有效地引用主内存中的一块地址。
局部性原理
局部性原理:在CPU访问存储设备时,无论是存取数据或存取指令,都趋于聚集在一片连续的区域中,这就被称为局部性原理。
- 时间局部性(
Temporal Locality):如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。比如程序中的循环、递归对数据的循环访问, 主要体现在指令读取的局部性 - 空间局部性(
Spatial Locality):如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。比如程序中的数据组的读取或者对象的连续创建, 对内存都是顺序的读写,主要体现在对程序数据引用的局部性
MESI协议
MESI是众多缓存一致性协议中的一种,也在Intel系列中广泛使用的缓存一致性协议
缓存行(Cache line)的状态有Modified、Exclusive、 Share 、Invalid,而MESI
命名正是以这4中状态的首字母来命名的。该协议要求在每个缓存行上维护两个状态位,使得每个数据单位可能处于M、E、S和I这四种状态之一。
| 状态 | 描述 | 监听任务 |
|---|---|---|
| M | 该Cache line有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中。 | 缓存行必须时刻监听所有试图读该缓存行相对就主存的操作,这种操作必须在缓存将该缓存行写回主存并将状态变成S(共享)状态之前被延迟执行。 |
| E | 该Cache line有效,数据和内存中的数据一致,数据只存在于本Cache中。 | 缓存行也必须监听其它缓存读主存中该缓存行的操作,一旦有这种操作,该缓存行需要变成S(共享)状态。 |
| S | 该Cache line有效,数据和内存中的数据一致,数据存在于很多Cache中。 | 缓存行也必须监听其它缓存使该缓存行无效或者独享该缓存行的请求,并将该缓存行变成无效(Invalid) |
| I | 该Cache line无效。 | 无 |
监听任务
- 一个处于M状态的缓存行,必须时刻监听所有试图读取该缓存行对应的主存地址的操作,如果监听到,则必须在此操作执行前把其缓存行中的数据写回主内存
- 一个处于S状态的缓存行,必须时刻监听使该缓存行无效或者独享该缓存行的请求,如果监听到,则必须把其缓存行状态设置为I。
- 一个处于E状态的缓存行,必须时刻监听其他试图读取该缓存行对应的主存地址的操作,如果监听到,则必须把其缓存行状态设置为S
嗅探协议
上面提到的监听任务大多数都是通过嗅探(snooping)协议来完成的
“窥探”背后的基本思想是,所有内存传输都发生在一条共享的总线上,而所有的处理器都能看到这条总线:缓存本身是独立的,但是内存是共享资源, 所有的内存访问都要经过仲裁(arbitrate):同一个指令周期中,只有一个缓存可以读写内存。窥探协议的思想是,缓存不仅仅在做内存传输的时候才和总线打交道, 而是不停地在窥探总线上发生的数据交换,跟踪其他缓存在做什么。所以当一个缓存代表它所属的处理器去读写内存时,其他处理器都会得到通知, 它们以此来使自己的缓存保持同步。只要某个处理器一写内存,其他处理器马上就知道这块内存在它们自己的缓存中对应的段已经失效。
MESI读取缓存流程
CPU1需要读取数据X,会根据数据的地址在自己的缓存L1A中找到对应的缓存行,然后判断缓存行的状态
- 如果缓存行的状态是
M、E、S,说明该缓存行的数据对于当前读请求是可用的,则可以直接使用 - 如果缓存行的状态是I,则说明该缓存行的数据是无效的,则CPU1会向总线发送
Read消息,说’我现在需要地址A的数据,谁可以提供?‘,其它处理器会CPU2监听总线上的消息,收到消息后,会从消息中解析出需要读取的地址, 然后在自己缓存中查找缓存行,这时候根据找到缓存行的状态会有以下几种情况- 状态为
S/E, CPU2会构造Read Response消息,将相应缓存行中的数据放到消息中,发送到总线同时更新自己缓存行的状态为S,CPU1收到响应消息后,会将消息中的数据存入相应的缓存行中,同时更新缓存行的状态为S - 状态为
M,会先将自己缓存行中的数据写入主内存,并响应Read Response消息同时将L1B中的相应的缓存行状态更新为S - 状态为I或者在自己的缓存中不存在X的数据,那么主内存会构造
Read Response消息,从主内存读取包含指定地址的块号数据放入消息(缓存行大小和内存块大小一致所以可以存放的下),并将消息发送到总线
- 状态为
- CPU1获接收到总线消息之后,解析出数据保存在自己的缓存中
MESI写缓存流程
CPU1 需要写入数据X
- 为
E/M时,说明当前CPU1已经拥有了相应数据的所有权,此时CPU1会直接将数据写入缓存行中,并更新缓存行状态为M,此时不需要向总线发送任何消息。 S时,说明数据被共享,其它CPU中有可能存有该数据的副本,则CPUA向总线发送Invalidate消息以获取数据的所有权,其它处理器(CPU2)收到Invalidate消息后,会将其高速缓存中相应的缓存行状态更新为I,表示已经逻辑删除相应的副本数据, 并回复Invalidate Acknowledge消息,CPU1收到所有处理器的响应消息后,会将数据更新到相应的缓存行之中,同时修改缓存行状态为E,此时拥有数据的所有权,会对缓存行数据进行更新,最终该缓存行状态为MI时,说明当前处理器中不包含该数据的有效副本,则CPU1向总线发送Read Invalidate消息,表明我要读数据X,希望主存告诉我X的值,同时请示其它处理器将自己缓存中包含该数据的缓存行并且状态不是I的缓存行置为无效`- 其它处理器(CPUB)收到
Invalidate消息后,如果缓存行不为I的话,会将其高速缓存中相应的缓存行状态更新为I,表示已经逻辑删除相应的副本数据,并回复Invalidate Acknowledge消息 - 主内存收到
Read消息后,会响应Read Response消息将需要读取的数据告诉CPU1 - CPU1收到所有处理器的
Invalidate Acknowledge消息和主内存的Read Response消息后,会将数据更新到相应的缓存行之中,同时修改缓存行状态为E,此时拥有数据的所有权,会对缓存行数据进行更新,最终该缓存行状态为M
MESI的状态变化
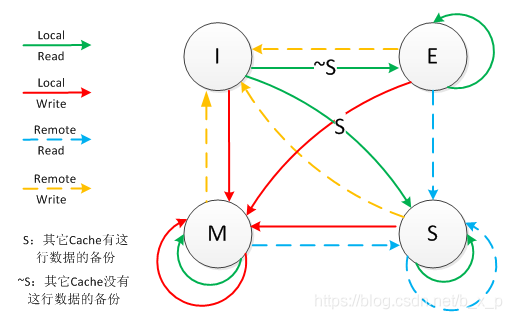
- Local Read:表示本内核读本Cache中的值
- Local Write:表示本内核写本Cache中的值
- Remote Read:表示其它内核读其Cache中的值
- Remote Write:表示其它内核写其Cache中的值
- 箭头表示本Cache line状态的迁移,环形箭头表示状态不变
StoreBuffer和Invalidate Queue
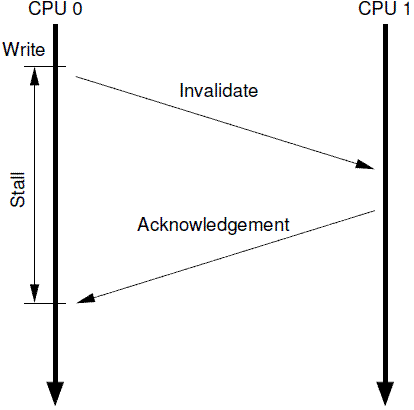
说了缓存一致性协议,好像就能够解决问题了,但是,在这里你会发现,又有新的问题出现了。MESI协议中:当cpu0写数据到本地cache的时候,如果不是M或者E状态,需要发送一个invalidate消息给cpu1,只有收到cpu1的ack之后cpu0才能继续执行,
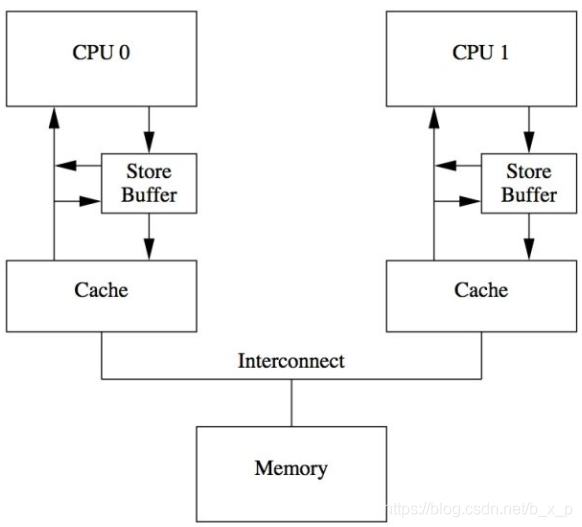
在这个过程中cpu0需要等待,这大大影响了性能。于是CPU设计者引入了Store Buffer,这个buffer处于CPU与cache之间。
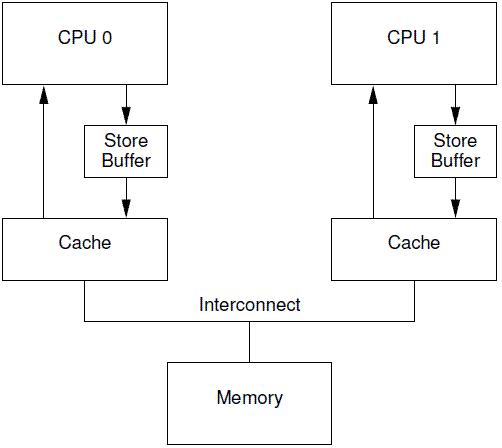
Store Buffer增加了CPU连续写的性能,同时把各个CPU之间的通信的任务交给缓存一致性协议。但是Store Buffer仍然引入了一些复杂性,那就是缓存数据和Store Buffer数据不一致的问题。
Store Forwarding
为了解决上面的问题,修改为了下面的架构,这种设计叫做Store forwarding,当CPU执行load操作的时候,不但要看cache,还有看Store Buffer是否有内容,如果Store Buffer有该数据,那么就采用Store Buffer中的值。
Invalid Queue
同样的问题也会出现在其他线程发送Invalidate Acknowledge消息的时候,通常Invalidate Cacheline操作没有那么快完成,尤其是在Cache繁忙的时候,这时CPU往往进行密集的load和store的操作,而来自其他CPU的,
对本CPU Cache的操作需要和本CPU的操作进行竞争,只有完成了invalidate操作之后,本CPU才会发生invalidate acknowledge。此外,如果短时间内收到大量的invalidate消息,CPU有可能跟不上处理,从而导致其他CPU不断的等待。
为了解决这个问题,引入了Invalid Queue,系统架构如下。
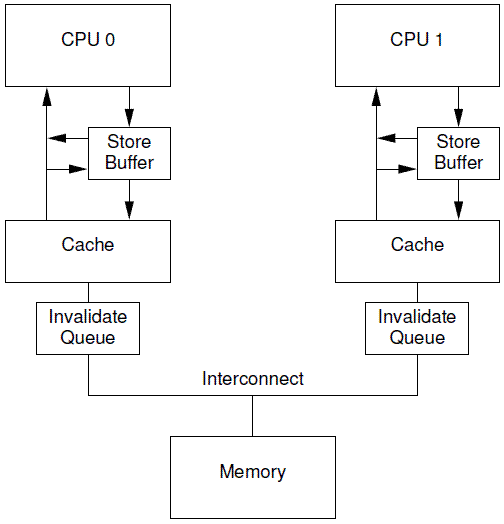
有了Invalidate Queue的CPU,在收到invalidate消息的时候首先把它放入Invalidate Queue,同时立刻回送acknowledge 消息,无需等到该cacheline被真正invalidate之后再回应。当然,如果本CPU想要针对某个cacheline向总线发送invalidate消息的时候,
那么CPU必须首先去Invalidate Queue中看看是否有相关的cacheline,如果有,那么不能立刻发送,需要等到Invalidate Queue中的cacheline被处理完之后再发送。
乱序执行/重排序
了解完上面的这些知识,我们再来整体的总结一下乱序执行或者说重排序的问题。
重排序从发生的环节上来分,可以分为2大类
- 编译器重排序
- 处理器重排序
下面我们分别来说一下。
编译器乱序
编译器重排序:编译器会对高级语言的代码进行分析,当编译器认为你的代码可以优化的话,编译器会选择对代码进行优化,重新排序,然后生成汇编代码。当然这个优化是有原则的,原则就是在保证单线程下的执行结果不变。
编译器在编译时候,能够获得最底层的信息,比如要读写哪个寄存器,读写哪块内存。所以编译就根据这些信息对代码进行优化,包括不限于减少无用变量、修改代码执行顺序等等。
优秀的编译器优化能够提升程序在CPU上的运行性能,更好的使用寄存器以及现代处理器的流水线技术,减少汇编指令的数量,降低程序执行需要的CPU周期,减少CPU读写主存的时间。
当然,编译器在优化的时候,只能保证在单线程下的结果,
demo
public class Main {
public static void main(String[] args) {
int A = 10;
int B = A + 10;
int C = 20;
}
}
假设编译器通过复杂的分析发现A不在缓存中,而C在缓存中,因此,A=10将触发多周期的数据加载,而C=20则可以在单个周期内完成,编译器可以直接跳过对A=10和B=A+10进行赋值操作而执行C=20>。
处理器乱序
- 在没有数据依赖的情况下,为提高流水线的工作效率,而对指令进行重排序
- 由于缓存的存在,虽然是按顺序执行,但是也会出现乱序的结果