Java对象头
锁升级和对象头关系很密切,所以我先了解一下对象头。
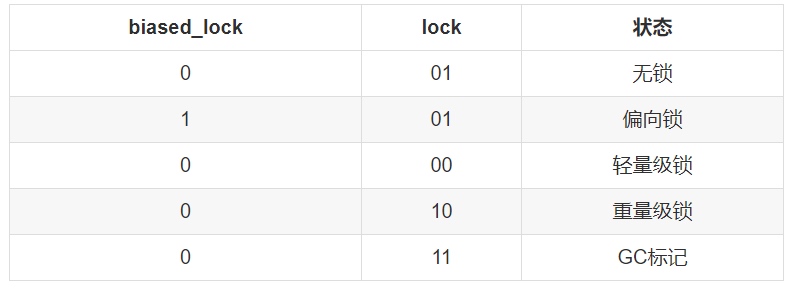
我们先来看一下64位系统下对象头的结构,对象头结构分为两部分Mark Word和Klass Word。我们主要关注Mark Word,klass word是指向这个对象的类对象的指针。
|--------------------------------------------------------------------------------------------------------------|
| Object Header (128 bits) |
|--------------------------------------------------------------------------------------------------------------|
| Mark Word (64 bits) | Klass Word (64 bits) |
|--------------------------------------------------------------------------------------------------------------|
| unused:25 | identity_hashcode:31 | unused:1 | age:4 | biased_lock:1 | lock:2 | OOP to metadata object | 无锁
|----------------------------------------------------------------------|--------|------------------------------|
| thread:54 | epoch:2 | unused:1 | age:4 | biased_lock:1 | lock:2 | OOP to metadata object | 偏向锁
|----------------------------------------------------------------------|--------|------------------------------|
| ptr_to_lock_record:62 | lock:2 | OOP to metadata object | 轻量锁
|----------------------------------------------------------------------|--------|------------------------------|
| ptr_to_heavyweight_monitor:62 | lock:2 | OOP to metadata object | 重量锁
|----------------------------------------------------------------------|--------|------------------------------|
| | lock:2 | OOP to metadata object | GC
|--------------------------------------------------------------------------------------------------------------|对象头的格式在处于不同锁级别的时候,格式有所不同。
- 无锁状态下,可以保存的数据有对象的hashCode,垃圾回收年龄,偏向标识,锁状态
- 偏向状态下,hashCode会被替换成,线程Id,和epoch,同时还有垃圾回收年龄,偏向标识,锁状态
- 轻量级状态下,保留了锁状态,其他部分都被替换成了指向Lock Record的指针。
- 重量级状态下,指向Lock Record的指针被替换成了指向一个Monitor对象的指针。
这里大家可能会有疑问,在各种锁状态下,都会有部分对象头中的数据被替换成了锁相关的数据,那么被替换的数据都去哪里了呢。
- 偏向锁,hashcode和偏向锁不能共存,在任何情况下调用hashcode,都会导致该锁对象的偏向锁失效。
- 如果在获得偏向锁之前调用了hashcode,会把对象头中的biased_lock设置为0
- 如果在获取锁之后的同步代码块中,调用hashcode,则会导致偏向撤销。
- 轻量级锁,会把被替换的对象头整体放到Lock Record中的 displaced_mark_word中
- 重量级锁,会放到monitor对象的_header中。 下面我们主要主要关注一下和锁状态关系比较密切的几个
biased_lock和lock
- biased_lock这个标志位表示当前这个锁对象是否可以偏向。0表示不可偏向 1表示可偏向。
- lock表示当前锁对象所处的锁级别
下面在开启偏向锁,并且过了4秒钟的默认偏向锁生效时间的前提下我们来分析。
- 创建出来的实例的对象头的后三位为
1 01,并且偏向的线程ID也为空,表示当前的实例状态是可偏向、没有偏向线程、没有锁定(也叫做匿名偏向状态) - 当有线程对这个实例加锁,这时候线程会偏向这个线程,既对象头中的线程ID修改为这个线程的ID,后三位为
1 01,这时候实例状态是,可偏向,偏向某一线程,没有锁定(这里为什么认为是没有锁定,我理解,就是把偏向锁也认为是无锁状态) - 这时候有另一个线程,尝试锁定这个实例,这时候会触发偏向锁的撤销,也就是把对象头中的biased_lock标志位从1改为0,并且升级到轻量级锁。这时候如果之前偏向的线程已经执行完毕,这个线程就能顺利的使用轻量级获得锁。这时候后三位是
0 00。这时候意思是不可偏向,已轻量级锁定 - 这时候如果另一个线程来尝试锁定,并且没有获取成功,会导致锁继续升级为重量级锁。这时候后三位是
0 10。这时候意思是不可偏向,已重量级锁定
epoch
epoch主要和批量重偏向次数有关,每当这个类型实例,发生了一次批量重偏向,就会把实例所属类型的epoch加1,同时把当前所有正在被线程使用的该类型的锁对象,对象头中的epoch加1,这个操作发生在安全点。 所以如果某些锁对象,如果发生批量重偏向的时候,没有被线程使用,那它的epoch就会小于类型中的epoch,当有线程尝试锁定这个锁对象的时候,则会直接进行一次重偏向。让这个锁对象,偏向当前的线程。
注意这里是把所有正在被线程使用的锁对象的epoch加1,因为上面重偏向逻辑的存在,所以需要保证正在被某个线程持有的锁对象,不会重新偏向给其他线程。
下面我就按照偏向锁、轻量级锁、重量级锁的顺序来详细了解一下加锁过程,和其中的关键部分。
锁升级整体流程
为什么要有锁升级
在jdk1.6之前,当一个线程获得synchronized,会阻塞后面的所有其他线程,而java的线程和操作系统的线程是一一映射的,所以阻塞和唤醒线程,都需要操作系统提供支持,都需要从用户态转入内核态,需要耗费大量的CPU的时间,这种状态转换用时可能比执行用户代码的时间还要长。所以在jdk1.6之前,synchronized都是一个重量级的操作,而在jdk1.6之后,对synchronized进行的优化,引入了偏向锁和轻量级锁的概念,使得synchronized的性能得到了很大的提升。jdk1.6之后的synchronized,从偏向锁到轻量级锁,再到重量级锁,让锁随着线程竞争的升级来逐渐升级。
在有一个线程访问的时候,使用偏向锁,只需要一次比较就能获得锁,性能最好。
在多个线程交替访问的时候,使用轻量级锁,只需要一次CAS操作就可以获得锁(这里说的交替,是指的线程不会同时去争抢锁。一个线程用完了,下一个线程再去获取)。
在存在线程竞争的时候,使用重量级锁。让没有获取到锁的线程进入阻塞状态,避免一些无效的自旋操作,节省CPU资源。
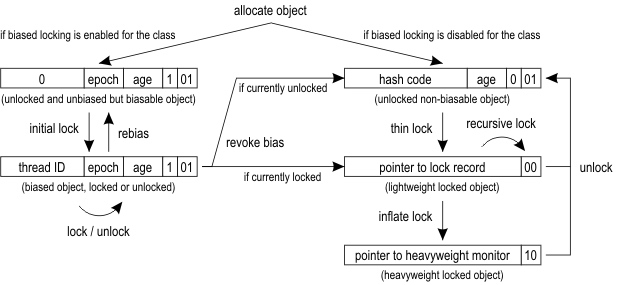 首先看一下这张图,这是Hotspot官方给出的锁升级过程图,我们先简单分析一下这张图。
首先看一下这张图,这是Hotspot官方给出的锁升级过程图,我们先简单分析一下这张图。
- 开启了偏向锁
- 锁对象刚分配的时候默认锁状态是匿名偏向状态。
- 有一个线程抢占锁,则在对象头中存储当前线程ID,锁进入偏向状态。
- 如果发生了重偏向,则会重新回到匿名偏向状态。
- 如果发生了偏向撤销。
- 如果发生的时候是无锁状态,则会进入不可偏向的无锁状态。
- 如果发生的时候是有线程正持有,则会进入轻量级加锁状态。
- 如果还有另一个线程尝试获取,并且获取失败,就会再升级到重量级。
- 轻量级和重量级在执行完同步代码之后,锁对象头会回到不可偏向的无锁状态。
- 偏向锁执行完同步代码之后,不会修改对象头,仍然保持上次的偏向状态。
- 没有开启偏向锁,则默认分配的就是不可偏向的无锁状态。
- 有线程尝试获取,则直接轻量级锁定
- 如果又有另一个线程获取锁,并且轻量级获取失败(也就是上一个线程还没有执行完同步代码),就会导致锁升级到重量级。
- 执行完同步代码,对象头回到初始的不可偏向无锁状态。
偏向锁
偏向锁被设计于优化单线程访问下的synchronized,在偏向锁下,只需要一个比较就能够获取锁。 下面我们从C++的源码来分析一下偏向锁的过程
偏向锁加锁
CASE(_monitorenter): {
oop lockee = STACK_OBJECT(-1);
// derefing's lockee ought to provoke implicit null check
CHECK_NULL(lockee);
// find a free monitor or one already allocated for this object
// if we find a matching object then we need a new monitor
// since this is recursive enter
BasicObjectLock* limit = istate->monitor_base();
BasicObjectLock* most_recent = (BasicObjectLock*) istate->stack_base();
BasicObjectLock* entry = NULL;
//从当前线程栈中获取一个空闲的BasicObjectLock
while (most_recent != limit ) {
if (most_recent->obj() == NULL) entry = most_recent;
else if (most_recent->obj() == lockee) break;
most_recent++;
}
//获取BasicObjectLock成功
if (entry != NULL) {
//将线程栈中的BasicObjectLock的obj指针指向锁对象
entry->set_obj(lockee);
int success = false;
uintptr_t epoch_mask_in_place = (uintptr_t)markOopDesc::epoch_mask_in_place;
//获取当前锁对象的对象头,用来进行下面的判断
markOop mark = lockee->mark();
intptr_t hash = (intptr_t) markOopDesc::no_hash;
// implies UseBiasedLocking
//判断锁对象是否是是偏向模式
if (mark->has_bias_pattern()) {
uintptr_t thread_ident;
uintptr_t anticipated_bias_locking_value;
thread_ident = (uintptr_t)istate->thread();
//下面这个操作,可以理解为为了方便进行后面的运算,可以说是比较骚的一种玩法,我们可以不用过分关注
anticipated_bias_locking_value =
(((uintptr_t)lockee->klass()->prototype_header() | thread_ident) ^ (uintptr_t)mark) &
~((uintptr_t) markOopDesc::age_mask_in_place);
//value = 0 表示已经偏向,并且偏向的就是自己,而且epoch和klass的epoch也相同,什么都不用做,直接获得偏向锁
if (anticipated_bias_locking_value == 0) {
// already biased towards this thread, nothing to do
if (PrintBiasedLockingStatistics) {
//如果需要统计偏向锁重入次数,可以使用biased_lock_entry_count_addr统计
(* BiasedLocking::biased_lock_entry_count_addr())++;
}
//标记状态为获取锁成功
success = true;
}
//对象的Klass的对象头不是偏向模式,则撤销偏向
else if ((anticipated_bias_locking_value & markOopDesc::biased_lock_mask_in_place) != 0) {
// try revoke bias
markOop header = lockee->klass()->prototype_header();
if (hash != markOopDesc::no_hash) {
header = header->copy_set_hash(hash);
}
if (Atomic::cmpxchg_ptr(header, lockee->mark_addr(), mark) == mark) {
if (PrintBiasedLockingStatistics)
(*BiasedLocking::revoked_lock_entry_count_addr())++;
}
}
//当前对象的对象头epoch不等于Klass中的epoch,则尝试重新偏向
else if ((anticipated_bias_locking_value & epoch_mask_in_place) !=0) {
// try rebias
markOop new_header = (markOop) ( (intptr_t) lockee->klass()->prototype_header() | thread_ident);
if (hash != markOopDesc::no_hash) {
new_header = new_header->copy_set_hash(hash);
}
//进行CAS将对象头中线程Id替换为自己,如果替换成功,则偏向成功
if (Atomic::cmpxchg_ptr((void*)new_header, lockee->mark_addr(), mark) == mark) {
if (PrintBiasedLockingStatistics)
(* BiasedLocking::rebiased_lock_entry_count_addr())++;
}
//替换失败,表示有多个线程并发争抢,则开始锁的升级
else {
CALL_VM(InterpreterRuntime::monitorenter(THREAD, entry), handle_exception);
}
success = true;
}
else {
//重新偏向, 如果markOop是匿名偏向的时候会偏向当前线程成功
//走到这里说明当前要么偏向别的线程,要么是匿名偏向(即没有偏向任何线程)
// try to bias towards thread in case object is anonymously biased
//构建一个匿名偏向的对象头
markOop header = (markOop) ((uintptr_t) mark & ((uintptr_t)markOopDesc::biased_lock_mask_in_place |
(uintptr_t)markOopDesc::age_mask_in_place |
epoch_mask_in_place));
if (hash != markOopDesc::no_hash) {
header = header->copy_set_hash(hash);
}
markOop new_header = (markOop) ((uintptr_t) header | thread_ident);
// debugging hint
DEBUG_ONLY(entry->lock()->set_displaced_header((markOop) (uintptr_t) 0xdeaddead);)
//进行CAS替换,如果替换成功,则偏向成功(只有markOop是匿名偏向的时候,才会替换成功)
if (Atomic::cmpxchg_ptr((void*)new_header, lockee->mark_addr(), header) == header) {
if (PrintBiasedLockingStatistics)
(* BiasedLocking::anonymously_biased_lock_entry_count_addr())++;
}
//失败,则升级
else {
CALL_VM(InterpreterRuntime::monitorenter(THREAD, entry), handle_exception);
}
success = true;
}
}
// traditional lightweight locking
//轻量级锁
if (!success) {
//设置当前的对象头为无锁状态,并且复制到Lock Record中的markoop中
markOop displaced = lockee->mark()->set_unlocked();
entry->lock()->set_displaced_header(displaced);
bool call_vm = UseHeavyMonitors;
//将对象头中的地址替换为指向Lock Record的指针,替换成功,则说明获取轻量级锁成功,则什么都不做。
//这里判断,如果是替换失败,则继续判断是否是锁重入。
if (call_vm || Atomic::cmpxchg_ptr(entry, lockee->mark_addr(), displaced) != displaced) {
// Is it simple recursive case?
//这里判断是不是锁重入,判断指向Lock Record的指针指向的地址是否属于当前线程栈
if (!call_vm && THREAD->is_lock_owned((address) displaced->clear_lock_bits())) {
//如果是轻量级锁的锁重入,说明前面set_displaced_header设置的是第一个Lock Record的地址,
//所以要重新将申请的Lock Record的displaced_header置为空,同样也会通过申请的displaced_header的个数来统计轻量级锁的重入次数
//栈的最高位的Lock Record的displaced_header不是空,重入锁退出锁的时候,会由低到高遍历退出,只在最后一个锁的时候使用CAS替换
entry->lock()->set_displaced_header(NULL);
} else {
//替换失败,则进行锁升级
CALL_VM(InterpreterRuntime::monitorenter(THREAD, entry), handle_exception);
}
}
}
UPDATE_PC_AND_TOS_AND_CONTINUE(1, -1);
} else {
istate->set_msg(more_monitors);
UPDATE_PC_AND_RETURN(0); // Re-execute
}
}通过代码我们可以知道在偏向锁的获取过程主要进行了几个判断
- 锁本省的偏向模式是否关闭
- 锁的epoch和proto header是否一致并且当前得前程ID和已经偏向的线程ID是否一致
- 锁类型的偏向模式(proto header)是否关闭
具体流程如下
- 获得一个可用的Lock Record,并把锁对象设置到lock record的obj中。
- 判断锁对象是否处于偏向模式
- 如果不是偏向模式,则直接走轻量级流程
- 是偏向模式
- 判断是不是已经偏向了当前线程,并且epoch和proto header中相同。并且proto header中也是偏向模式
- 如果是,则设置success = true,表示直接获取成功。
- 如果不是,则判断proto header中是否关闭了偏向模式
- 如果proto header关闭了偏向模式,则构建一个通过proto header构建一个新的对象头,并CAS设置到锁对象头中,完成偏向撤销,然后走轻量级逻辑。
(对象头状态: 偏向模式->撤销偏向)
- 如果proto header关闭了偏向模式,则构建一个通过proto header构建一个新的对象头,并CAS设置到锁对象头中,完成偏向撤销,然后走轻量级逻辑。
- 如果没有关闭,则继续判断,是不是epoch不同
- 如果是epoch不同,则表示发生了批量重偏向,然后构建一个偏向当前线程的对象头,然后CAS设置到锁对象头。
- 如果CAS成功,则设置success = true,表示获取偏向锁成功。
(对象头状态: 偏向其他线程->重新偏向当前线程) - 如果CAS失败,则表示在这一步发生了线程并发获取锁的操作,则直接调用
monitorenter锁升级。
- 如果CAS成功,则设置success = true,表示获取偏向锁成功。
- 如果是epoch不同,则表示发生了批量重偏向,然后构建一个偏向当前线程的对象头,然后CAS设置到锁对象头。
- 如果都不满足上面的情况,那就是标明,当前锁对象头处于匿名偏向状态,或者偏向了其他线程,那构建一个偏向当前线程的对象头,和匿名偏向的对象头,然后CAS替换到锁对象头中,这里只有锁是匿名偏向状态的时候才会替换成功
- 如果设置成功,则设置success= true,表示获取偏向锁成功。
(对象头状态: 匿名偏向->偏向当前线程) - 如果设置失败,说明锁已经偏向了其他线程,则直接调用
monitorenter锁升级。
- 如果设置成功,则设置success= true,表示获取偏向锁成功。
- 判断是不是已经偏向了当前线程,并且epoch和proto header中相同。并且proto header中也是偏向模式
偏向锁撤销
如果一直只有一个线程持有这个锁,那么这个锁会一直保持偏向状态,并且获取所得操作只需要一次判断,效率最高。
如果一旦出现了另一个线程,尝试获取这个锁对象,就会触发偏向锁的撤销。
偏向撤销,是指把锁对象头中的bias_lock修改为0,这样可以让后续的获取锁的步骤中,跳过偏向流程,直接进入轻量级逻辑。
撤销会有三种情况
1. 锁对象处于匿名偏向状态时发起的偏向撤销。比如这个锁对象在没有被任何线程获取之前,调用了hashcode()方法。
2. 持有偏向锁的线程自己发起的偏向撤销,比如在同步方法里调用了hashcode()方法。
3. 一个线程持有偏向锁,另一个线程也尝试获取,导致的偏向撤销。
前两种情况的撤销,不会对任何线程产生影响,所以可以不用等待安全点,直接操作就行。而且第一种,因为没有任何线程获取过它,所以直接使用CAS操作替换就行。 第三种情况,因为直接撤销的话,有可能会对正持有偏向锁的线程产生影响,为了避免这种影响,所以需要在安全点来进行。
下面我们通过代码来分析一下这个过程。
fast_enter
//obj 是锁对象
//lock 是线程栈中的 lock record,存储了displaced header
//attempt_rebias 是是否允许重偏向,我们这里是true
void ObjectSynchronizer::fast_enter(Handle obj, BasicLock* lock,
bool attempt_rebias, TRAPS) {
//判断是否开启偏向锁,如果没开启这走slow_enter升级
if (UseBiasedLocking) {
//判断是否是业务线程触发的撤销
if (!SafepointSynchronize::is_at_safepoint()) {
BiasedLocking::Condition cond = BiasedLocking::revoke_and_rebias(obj, attempt_rebias, THREAD);
if (cond == BiasedLocking::BIAS_REVOKED_AND_REBIASED) {
return;
}
} else {
//这里表示是由vm线程触发的
assert(!attempt_rebias, "can not rebias toward VM thread");
BiasedLocking::revoke_at_safepoint(obj);
}
assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now");
}
//执行锁升级
slow_enter(obj, lock, THREAD);
}revoke_and_rebias
我们先列举一下这个方法的返回值
- BIAS_REVOKED_AND_REBIASED 偏向撤销并已重偏向
- BIAS_REVOKED 偏向已撤销
- NOT_BIASED 没有偏向
我们看到fast_enter的逻辑中,只要revoke_and_rebias()方法返回的不是BIAS_REVOKED_AND_REBIASED,那么最终都会执行到slow_enter中进行锁升级。
下面我们来看revoke_and_rebias()方法的实现。
BiasedLocking::Condition BiasedLocking::revoke_and_rebias(Handle obj, bool attempt_rebias, TRAPS) {
assert(!SafepointSynchronize::is_at_safepoint(), "must not be called while at safepoint");
// We can revoke the biases of anonymously-biased objects
// efficiently enough that we should not cause these revocations to
// update the heuristics because doing so may cause unwanted bulk
// revocations (which are expensive) to occur.
//获取锁的对象头
markOop mark = obj->mark();
//1. 如果不允许重新偏向,并且锁处于匿名偏向
if (mark->is_biased_anonymously() && !attempt_rebias) {
// We are probably trying to revoke the bias of this object due to
// an identity hash code computation. Try to revoke the bias
// without a safepoint. This is possible if we can successfully
// compare-and-exchange an unbiased header into the mark word of
// the object, meaning that no other thread has raced to acquire
// the bias of the object.
markOop biased_value = mark;
//构建撤销了偏向模式的对象头
markOop unbiased_prototype = markOopDesc::prototype()->set_age(mark->age());
//CAS替换锁对象的对象头
markOop res_mark = (markOop)Atomic::cmpxchg_ptr(unbiased_prototype, obj->mark_addr(), mark);
//如果替换成功,则撤销完成,然后通过slow_enter进行锁升级即可
//如果替换失败,说明此时锁已经被其他线程获取,则会通过下面的逻辑走由JVM线程发起的单个撤销
if (res_mark == biased_value) {
return BIAS_REVOKED;
}
//2. 如果不是匿名偏向,或者是允许重偏向,并且锁对象是偏向模式
//这里大多数情况是,锁偏向了某个线程。
} else if (mark->has_bias_pattern()) {
Klass* k = obj->klass();
//获取Klass的markOop
markOop prototype_header = k->prototype_header();
//2.1. 如果Klass的Oop不是偏向模式则执行
//表示锁对象所属的类型,已经关闭了偏向模式,发生了批量撤销
if (!prototype_header->has_bias_pattern()) {
// This object has a stale bias from before the bulk revocation
// for this data type occurred. It's pointless to update the
// heuristics at this point so simply update the header with a
// CAS. If we fail this race, the object's bias has been revoked
// by another thread so we simply return and let the caller deal
// with it.
markOop biased_value = mark;
markOop res_mark = (markOop) Atomic::cmpxchg_ptr(prototype_header, obj->mark_addr(), mark);
assert(!(*(obj->mark_addr()))->has_bias_pattern(), "even if we raced, should still be revoked");
return BIAS_REVOKED;
//2.2 . 如果Klass markOop和锁对象的markOop的epoch不同,则执行
//这里是说明锁对象仍然处于偏向模式,但是发生了一次批量重偏向,导致epoch不同了
} else if (prototype_header->bias_epoch() != mark->bias_epoch()) {
// The epoch of this biasing has expired indicating that the
// object is effectively unbiased. Depending on whether we need
// to rebias or revoke the bias of this object we can do it
// efficiently enough with a CAS that we shouldn't update the
// heuristics. This is normally done in the assembly code but we
// can reach this point due to various points in the runtime
// needing to revoke biases.
// 如果允许重偏向
if (attempt_rebias) {
assert(THREAD->is_Java_thread(), "");
markOop biased_value = mark;
//构建一个偏向当前线程的对象头
markOop rebiased_prototype = markOopDesc::encode((JavaThread*) THREAD, mark->age(), prototype_header->bias_epoch());
//cas替换
markOop res_mark = (markOop) Atomic::cmpxchg_ptr(rebiased_prototype, obj->mark_addr(), mark);
// 如果替换成功,返回BIAS_REVOKED_AND_REBIASED,表示获取锁成功
//替换失败,则走下面的偏向撤销流程
if (res_mark == biased_value) {
return BIAS_REVOKED_AND_REBIASED;
}
} else {
// 如果不允许重偏向,则进行偏向撤销
markOop biased_value = mark;
markOop unbiased_prototype = markOopDesc::prototype()->set_age(mark->age());
markOop res_mark = (markOop) Atomic::cmpxchg_ptr(unbiased_prototype, obj->mark_addr(), mark);
if (res_mark == biased_value) {
return BIAS_REVOKED;
}
}
}
}
//3. 如果锁对象已经偏向了某个线程,而且proto header中偏向模式没有关闭,
//epoch 也相同的话(也就是偏向了某个线程,但是没有发生批量重偏向和批量撤销)
//则后走下面的逻辑
//update_heuristics 这个方法就是决定接下来改进行什么样的操作
HeuristicsResult heuristics = update_heuristics(obj(), attempt_rebias);
if (heuristics == HR_NOT_BIASED) {
return NOT_BIASED;
} else if (heuristics == HR_SINGLE_REVOKE) {
//3.1 开始单个撤销
Klass *k = obj->klass();
markOop prototype_header = k->prototype_header();
//当前对象偏向当前线程,并且对象的epoch和Klass的Epoch相同,则直接开始执行撤销,
//也就是说是线程自己发起的偏向撤销,就是我们上面提到的在同步代码中,调用了hashcode方法
if (mark->biased_locker() == THREAD &&
prototype_header->bias_epoch() == mark->bias_epoch()) {
// A thread is trying to revoke the bias of an object biased
// toward it, again likely due to an identity hash code
// computation. We can again avoid a safepoint in this case
// since we are only going to walk our own stack. There are no
// races with revocations occurring in other threads because we
// reach no safepoints in the revocation path.
// Also check the epoch because even if threads match, another thread
// can come in with a CAS to steal the bias of an object that has a
// stale epoch.
ResourceMark rm;
if (TraceBiasedLocking) {
tty->print_cr("Revoking bias by walking my own stack:");
}
//因为是自己线程发起的,所以直接进行撤销操作,不需要等待安全点,这里allow_rebias 也是false
BiasedLocking::Condition cond = revoke_bias(obj(), false, false, (JavaThread*) THREAD);
((JavaThread*) THREAD)->set_cached_monitor_info(NULL);
assert(cond == BIAS_REVOKED, "why not?");
return cond;
} else {
//3.2 如果需要撤销的不是当前线程,则需要等待线程安全点,之后Jvm在线程安全点会触发撤销程序
VM_RevokeBias revoke(&obj, (JavaThread*) THREAD);
VMThread::execute(&revoke);
return revoke.status_code();
}
}
//批量撤销和批量重偏向,注意这里,会把attempt_rebias传过去
assert((heuristics == HR_BULK_REVOKE) ||
(heuristics == HR_BULK_REBIAS), "?");
VM_BulkRevokeBias bulk_revoke(&obj, (JavaThread*) THREAD,
(heuristics == HR_BULK_REBIAS),
attempt_rebias);
VMThread::execute(&bulk_revoke);
return bulk_revoke.status_code();
}首先
- 判断: 是否处于匿名偏向状态,并且不允许重新偏向
- 这是我们上面说到的撤销的第一种情况,在同步代码块执行前,调用了锁对象的hashcode()方法。
- 判断:是否锁对象处于偏向模式,包括匿名偏向和偏向了某一个线程
- 判断: 是否Class已经关闭了偏向模式
- 说明发生了偏向撤销
- 直接使用Class的proto header替换锁对象的对象头,完成撤销操作
- 判断: 锁对象和Class的epoch是否不同
- epoch不同说明,发生了批量重偏向
- 根据attempt_rebias来处理,如果为true则尝试重偏向,如果为false,则执行偏向撤销
- 判断: 是否Class已经关闭了偏向模式
- 无法简单的判断如何操作,需要根据Class中记录的偏向撤销信息来进行决策
- 走到这里条件是:已经偏向了某个线程、Class的偏向模式没有关闭、epoch相同
- 如果是返回
HR_SINGLE_REVOKE- 判断: 当前线程是否为持有锁线程,并且epoch相同。
- 这里是我们上面提到的撤销3种情况中的,在同步代码快中调用了hashcode()方法
- 如果是则直接由当前线程调用
revoke_bias完成撤销,因为自己发起的,不会导致持有锁线程的异常。 - 如果不是,则需要交给JVM线程,在安全点调用
revoke_bias完成撤销。
- 判断: 当前线程是否为持有锁线程,并且epoch相同。
- 如果返回的
HR_BULK_REVOKE和HR_BULK_REBIAS,则由JVM线程,在安全点完成批量撤销和批量重偏向。
update_heuristics
JVM通过这个方法来进行偏向撤销的决策。 先说一下这个决策的数据依据。
- 每个锁对象,发生一次偏向撤销,都会在这个锁对象所属的Class中记录下来,称谓偏向撤销次数
- 每当发生了批量撤销,也会记录下来最近一次发生的时间。
用户设置的批量重偏向阈值和批量撤销阈值,新一次批量重偏向延迟时间
-XX:BiasedLockingBulkRebiasThreshold=20 偏向锁批量重偏向阈值 -XX:BiasedLockingBulkRevokeThreshold=40 偏向锁批量撤销阈值
JVM就是根据上面这些数据来进行计算决策的。
static HeuristicsResult update_heuristics(oop o, bool allow_rebias) {
markOop mark = o->mark();
//如果不是偏向模式直接返回
if (!mark->has_bias_pattern()) {
return HR_NOT_BIASED;
}
// 锁对象的类
Klass* k = o->klass();
// 当前时间
jlong cur_time = os::javaTimeMillis();
// 上一次批量撤销或者批量重偏向的时间
// 因为批量撤销和批量重偏向都是同一个方法,所以都会更新这个时间
jlong last_bulk_revocation_time = k->last_biased_lock_bulk_revocation_time();
// 该类偏向锁撤销的次数
int revocation_count = k->biased_lock_revocation_count();
// BiasedLockingBulkRebiasThreshold是重偏向阈值(默认20),
//BiasedLockingBulkRevokeThreshold是批量撤销阈值(默认40),
//BiasedLockingDecayTime是开启一次新的批量重偏向距离上次批量重偏向或者批量撤销后的延迟时间,默认25000。也就是开启批量重偏向后,
//经过了一段较长的时间(>=BiasedLockingDecayTime),撤销计数器才超过阈值,那我们会重置计数器。
if ((revocation_count >= BiasedLockingBulkRebiasThreshold) &&
(revocation_count < BiasedLockingBulkRevokeThreshold) &&
(last_bulk_revocation_time != 0) &&
(cur_time - last_bulk_revocation_time >= BiasedLockingDecayTime)) {
// This is the first revocation we've seen in a while of an
// object of this type since the last time we performed a bulk
// rebiasing operation. The application is allocating objects in
// bulk which are biased toward a thread and then handing them
// off to another thread. We can cope with this allocation
// pattern via the bulk rebiasing mechanism so we reset the
// klass's revocation count rather than allow it to increase
// monotonically. If we see the need to perform another bulk
// rebias operation later, we will, and if subsequently we see
// many more revocation operations in a short period of time we
// will completely disable biasing for this type.
k->set_biased_lock_revocation_count(0);
revocation_count = 0;
}
// 自增撤销计数器
if (revocation_count <= BiasedLockingBulkRevokeThreshold) {
revocation_count = k->atomic_incr_biased_lock_revocation_count();
}
// 如果达到批量撤销阈值则返回HR_BULK_REVOKE
if (revocation_count == BiasedLockingBulkRevokeThreshold) {
return HR_BULK_REVOKE;
}
// 如果达到批量重偏向阈值则返回HR_BULK_REBIAS
if (revocation_count == BiasedLockingBulkRebiasThreshold) {
return HR_BULK_REBIAS;
}
// 没有达到阈值则撤销单个对象的锁
return HR_SINGLE_REVOKE;
}- 获取偏向撤销次数、上次批量撤销的时间
- 然后就是一个比较长的判断
- 撤销次数大于等于重偏向阈值20,小于批量撤销阈值40,并且发生过重偏向或者批量撤销,并且距离上次发生的时间超过了25000ms,那么我们就把撤销次数清零。
- 这个判断的意思是,如果一个类型发生过批量操作,但是在接下来的很长时间内,都没有达到下一次批量操作的触发条件,那么JVM就会认为,这个类型的锁对象线程争抢不严重,为了避免它达到批量撤销阈值,从而再也不能使用偏向模式,而把撤销计数归0
- 然后就是根据撤销计数返回对应的撤销类型了。
revoke_bias
update_heuristics 返回对应的撤销决策之后,后面就要根据决策进行具体的处理了。 我们先看单个撤销revoke_bias
static BiasedLocking::Condition revoke_bias(oop obj, bool allow_rebias, bool is_bulk, JavaThread* requesting_thread) {
markOop mark = obj->mark();
// 如果没有开启偏向模式,则直接返回NOT_BIASED
if (!mark->has_bias_pattern()) {
...
return BiasedLocking::NOT_BIASED;
}
uint age = mark->age();
// 构建两个mark word,一个是匿名偏向模式(101),一个是无锁模式(001)
markOop biased_prototype = markOopDesc::biased_locking_prototype()->set_age(age);
markOop unbiased_prototype = markOopDesc::prototype()->set_age(age);
...
JavaThread* biased_thread = mark->biased_locker();
if (biased_thread == NULL) {
// 匿名偏向。当调用锁对象的hashcode()方法可能会导致走到这个逻辑
// 这里我也有点疑问,如果是匿名偏向状态,这表示没有被线程获取过,那么在revoke_and_bias的逻辑中应该可以CAS成功,如果那里失败,这里也不会是匿名偏向模式了
// 如果不允许重偏向,则将对象的mark word设置为无锁模式
if (!allow_rebias) {
obj->set_mark(unbiased_prototype);
}
...
return BiasedLocking::BIAS_REVOKED;
}
// code 1:判断偏向线程是否还存活
bool thread_is_alive = false;
// 如果当前线程就是偏向线程
if (requesting_thread == biased_thread) {
thread_is_alive = true;
} else {
// 遍历当前jvm的所有线程,如果能找到,则说明偏向的线程还存活
for (JavaThread* cur_thread = Threads::first(); cur_thread != NULL; cur_thread = cur_thread->next()) {
if (cur_thread == biased_thread) {
thread_is_alive = true;
break;
}
}
}
// 如果偏向的线程已经不存活了
if (!thread_is_alive) {
// 允许重偏向则将对象mark word设置为匿名偏向状态,否则设置为无锁状态
if (allow_rebias) {
obj->set_mark(biased_prototype);
} else {
//如果不允许,就设置为偏向撤销状态
obj->set_mark(unbiased_prototype);
}
...
return BiasedLocking::BIAS_REVOKED;
}
// 线程还存活则遍历线程栈中所有的Lock Record
GrowableArray<MonitorInfo*>* cached_monitor_info = get_or_compute_monitor_info(biased_thread);
BasicLock* highest_lock = NULL;
for (int i = 0; i < cached_monitor_info->length(); i++) {
MonitorInfo* mon_info = cached_monitor_info->at(i);
// 如果能找到对应的Lock Record说明偏向的线程还在执行同步代码块中的代码
if (mon_info->owner() == obj) {
...
// 需要升级为轻量级锁,直接修改偏向线程栈中的Lock Record。
//为了处理锁重入的case,在这里将Lock Record的Displaced Mark Word
//设置为null,第一个Lock Record会在下面的代码中再处理
markOop mark = markOopDesc::encode((BasicLock*) NULL);
highest_lock = mon_info->lock();
highest_lock->set_displaced_header(mark);
} else {
...
}
}
if (highest_lock != NULL) {
// 修改第一个Lock Record为无锁状态,然后将obj的mark word设置为指向该Lock Record的指针
highest_lock->set_displaced_header(unbiased_prototype);
obj->release_set_mark(markOopDesc::encode(highest_lock));
...
} else {
// 走到这里说明偏向线程已经不在同步块中了
...
if (allow_rebias) {
//设置为匿名偏向状态
// 目前从代码中,只发现了会在批量重偏向的时候,allow_rebias会是true,从fast_enter带过来,然后传到VM_BulkRevokeBias
obj->set_mark(biased_prototype);
} else {
// 将mark word设置为无锁状态
obj->set_mark(unbiased_prototype);
}
}
return BiasedLocking::BIAS_REVOKED;
}上面的撤销逻辑看似比较长,其实核心逻辑并不复杂:
- 如果当前对象锁已经不是偏向模式了,就不用执行撤销。
- 如果当前锁对象偏向的线程Id为NULL,也就是没有偏向任何线程,就根据参数allow_rebias判断是否允许重新偏向,不允许就设置锁状态为无锁,相当于撤销偏向。
- 判断当前锁对象中偏向的线程是否存活,如果持有偏向锁的线程已经死掉了,那如果允许重新偏向就设置对象头锁状态为偏向锁的初始状态,不允许就设置为无锁状态。
- 如果线程还存活,就开始执行真正的撤销了:
这里回忆一下前面偏向锁的获取和退出流程:偏向锁的获取,就是在当前线程的线程栈中申请一块Lock Record,然后将Lock Record的obj指向锁对象,并且在对象头中存储当前线程的线程Id。而偏向锁的退出,仅仅将Lock Record中的obj值置为空,其他的什么都没有做。
- 如果持有偏向锁的线程依旧存活,这里就有两种情况
- 持有偏向锁的线程还没有退出同步代码块
- 第二是持有偏向锁的线程退出了同步代码块。
- 而判断是否已经退出,判断依据就是线程栈中是否还有指向锁对象的Lock Record,这以上面的代码中,首先就是遍历线程栈,判断持有锁的线程是否退出了。
- 遍历结束后,如果highest_lock不等于空,说还没有退出,如果等于NULL说明已经退出了。
- 如果还在代码块中没有退出,就需要升级锁为轻量级锁,升级为轻量级锁业很简单,先将Lock Record的displaced_header设置为无锁的markoop,在把锁对象头替换成指向LockRecord的指针。
- 后面看完轻量级锁,再回过头看这里的升级过程,就会明白了。
- 如果持有偏向锁的线程已经退出了,则判断是否允许重新偏向,如果允许重新偏向,就设置锁对象的对象头为匿名偏向状态。否则设置为轻量级无锁状态,即撤销偏向锁。
批量重偏向,批量撤销
当只有一个线程A反复进入同步块时,偏向锁带来的性能开销基本可以忽略,但是当线程B尝试获得锁时,就需要等到safe point时交给JVM将偏向锁撤销为无锁状态或升级为轻量级/重量级锁。(因为锁已经被线程A持有,线程B不能修改锁的状态,因为会影响线程A。所以叫给JVM来修改锁的状态)safe point这个词我们在GC中经常会提到,其代表了一个状态,在该状态下所有线程都是暂停的(STW)。总之,偏向锁的撤销是有一定成本的,如果说运行时的场景本身存在多线程竞争的,那偏向锁的存在不仅不能提高性能,而且会导致性能下降。因此,JVM中增加了一种批量重偏向/撤销的机制。
- 一个线程创建了大量对象并执行了初始的同步操作,之后在另一个线程中将这些对象作为锁进行之后的操作。这种case下,会导致大量的偏向锁撤销操作。
- 存在明显多线程竞争的场景下使用偏向锁是不合适的,例如生产者/消费者队列。
批量重偏向(bulk rebias)机制是为了解决第一种场景。批量撤销(bulk revoke)则是为了解决第二种场景。
JVM以class为单位,为每个class维护一个偏向锁撤销计数器,每一次该class的对象发生偏向撤销操作时,该计数器+1。然后根据撤销计数器来决定是否触发批量操作,具体逻辑可以查看上面的 update_heuristics方法逻辑。
下面我们看代码。
最终批量重偏向和批量撤销都会调用到bulk_revoke_or_rebias_at_safepoint方法。
static BiasedLocking::Condition bulk_revoke_or_rebias_at_safepoint(oop o,
bool bulk_rebias,
bool attempt_rebias_of_object,
JavaThread* requesting_thread) {
...
jlong cur_time = os::javaTimeMillis();
//记录本次批量操作的时间
o->klass()->set_last_biased_lock_bulk_revocation_time(cur_time);
Klass* k_o = o->klass();
Klass* klass = k_o;
if (bulk_rebias) {
// 批量重偏向的逻辑
if (klass->prototype_header()->has_bias_pattern()) {
// 拿到类中的epoch
int prev_epoch = klass->prototype_header()->bias_epoch();
// code 1:把类中的epoch自增加1
klass->set_prototype_header(klass->prototype_header()->incr_bias_epoch());
// 获取到自增后的类epoch
int cur_epoch = klass->prototype_header()->bias_epoch();
// code 2:遍历所有线程的栈,更新所有该类型锁实例的epoch
// 这里很重要,这里是遍历的线程栈,也就是表示是当前正在使用的偏向锁
//也就是说,这里是找到所有当前正在被线程持有的,或者说正在同步代码块中执行的偏向锁对象
//然后把它们的epoch和类的epoch保持一致。
//这么做的目的是,因为线程在获取偏向锁的时候,会比较锁的epoch和类型epoch是否相同
//如果不同的话,会进行重偏向操作。所以为了避免,当前正在使用的锁,别其他线程获取,
//所以这里会把当前正在使用的锁,和类的epoch保持一致
for (JavaThread* thr = Threads::first(); thr != NULL; thr = thr->next()) {
GrowableArray<MonitorInfo*>* cached_monitor_info = get_or_compute_monitor_info(thr);
for (int i = 0; i < cached_monitor_info->length(); i++) {
MonitorInfo* mon_info = cached_monitor_info->at(i);
oop owner = mon_info->owner();
markOop mark = owner->mark();
if ((owner->klass() == k_o) && mark->has_bias_pattern()) {
// We might have encountered this object already in the case of recursive locking
assert(mark->bias_epoch() == prev_epoch || mark->bias_epoch() == cur_epoch, "error in bias epoch adjustment");
owner->set_mark(mark->set_bias_epoch(cur_epoch));
}
}
}
}
// 接下来对当前锁对象进行重偏向
//没错这里也是调用的 revoke_bias,不过第三个参数 is_bulk 为true
revoke_bias(o, attempt_rebias_of_object && klass->prototype_header()->has_bias_pattern(), true, requesting_thread);
} else {
...
// code 3:批量撤销的逻辑,将类中的偏向标记关闭,markOopDesc::prototype()返回的是一个关闭偏向模式的prototype
klass->set_prototype_header(markOopDesc::prototype());
// code 4:遍历所有线程的栈,撤销该类所有锁的偏向
//这里和上面批量重偏向一样,撤销的也是当前被使用的锁对象
for (JavaThread* thr = Threads::first(); thr != NULL; thr = thr->next()) {
GrowableArray<MonitorInfo*>* cached_monitor_info = get_or_compute_monitor_info(thr);
for (int i = 0; i < cached_monitor_info->length(); i++) {
MonitorInfo* mon_info = cached_monitor_info->at(i);
oop owner = mon_info->owner();
markOop mark = owner->mark();
// 判断锁是否该类型的,并且开启了偏向模式
if ((owner->klass() == k_o) && mark->has_bias_pattern()) {
//执行偏向撤销,并且allow_rebias 为false,is_bulk 为true
revoke_bias(owner, false, true, requesting_thread);
}
}
}
// 撤销当前锁对象的偏向模式
revoke_bias(o, false, true, requesting_thread);
}
...
BiasedLocking::Condition status_code = BiasedLocking::BIAS_REVOKED;
//在执行完批量操作后,如果允许重偏向,并且锁对象和类都处于偏向模式
//那么就让这个锁对象直接重偏向到当前线程,因为这里是安全点,所以直接设置即可,不需要考虑并发。
if (attempt_rebias_of_object &&
o->mark()->has_bias_pattern() &&
klass->prototype_header()->has_bias_pattern()) {
// 构造一个偏向请求线程的mark word
markOop new_mark = markOopDesc::encode(requesting_thread, o->mark()->age(),
klass->prototype_header()->bias_epoch());
// 更新当前锁对象的mark word
o->set_mark(new_mark);
status_code = BiasedLocking::BIAS_REVOKED_AND_REBIASED;
...
}
...
return status_code;
}这个方法的整体逻辑还是比较清晰的。
- 首先记录本次批量操作的时间
- 然后根据类型是批量重偏向还是批量撤销
- 然后都是遍历所有的线程栈,找到仍然在使用的锁对象
- 重偏向的修改epoch,然后执行偏向撤销
- 批量撤销的,就执行偏向撤销
- 批量操作完成之后,如果锁对象和class仍然处于偏向模式,并且是允许重偏向的,那么就把锁对象偏向到当前线程。
我觉的这里的一个关键点就是,要理解批量操作的锁对象,都是正在被线程使用的。其他没有被操作的锁对象,需要等待。
偏向锁释放
CASE(_monitorexit): {
oop lockee = STACK_OBJECT(-1);
CHECK_NULL(lockee);
// derefing's lockee ought to provoke implicit null check
// find our monitor slot
BasicObjectLock* limit = istate->monitor_base();
BasicObjectLock* most_recent = (BasicObjectLock*) istate->stack_base();
//循环遍历线程栈中的Lock Record
while (most_recent != limit ) {
//如果Lock Record的Obj指向的是当前锁对象,说明是当前锁对象的Lock Record
if ((most_recent)->obj() == lockee) {
BasicLock* lock = most_recent->lock();
markOop header = lock->displaced_header();
//将obj设置为Null
most_recent->set_obj(NULL);
//如果不是偏向模式(即是轻量级锁),下面是轻量级模式。
if (!lockee->mark()->has_bias_pattern()) {
bool call_vm = UseHeavyMonitors;
// If it isn't recursive we either must swap old header or call the runtime
if (header != NULL || call_vm) {
//将对象头中的markoop替换为Lock Record中的markoop
if (call_vm || Atomic::cmpxchg_ptr(header, lockee->mark_addr(), lock) != lock) {
// restore object for the slow case
//如果替换失败,则还原Lock Record,并且执行锁升级的monitorexit
most_recent->set_obj(lockee);
CALL_VM(InterpreterRuntime::monitorexit(THREAD, most_recent), handle_exception);
}
}
}
UPDATE_PC_AND_TOS_AND_CONTINUE(1, -1);
}
most_recent++;
}
// Need to throw illegal monitor state exception
CALL_VM(InterpreterRuntime::throw_illegal_monitor_state_exception(THREAD), handle_exception);
ShouldNotReachHere();
}- 遍历当前线程栈中的所有的Lock Record, 如果Lock Record的obj指向的是自己,则说明当前的Lock Record属于当前锁对象。
- 将Lock Record的obj设置为空。如果是偏向锁,则就不做其他操作了。
- 如果是轻量级锁,后面再说明。
HashCode和偏向锁
在上面时,我们提到当调用hashCode的时候,会引起偏向撤销,我们先用Java代码模拟一下这个情况。
在同步代码中调用锁的hashcode对锁状态的影响
public class HashCodeAndBiasLock {
/*
依赖
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.14</version>
</dependency>
*/
public static void main(String[] args) throws InterruptedException {
Thread.sleep(5000);
BiasLock lock = new BiasLock();
System.out.println("初始状态");
System.out.println(ClassLayout.parseInstance(lock).toPrintable());
synchronized (lock){
System.out.println("加锁状态");
System.out.println(ClassLayout.parseInstance(lock).toPrintable());
lock.hashCode();
System.out.println("hashcode后状态");
System.out.println(ClassLayout.parseInstance(lock).toPrintable());
}
}
}执行结果
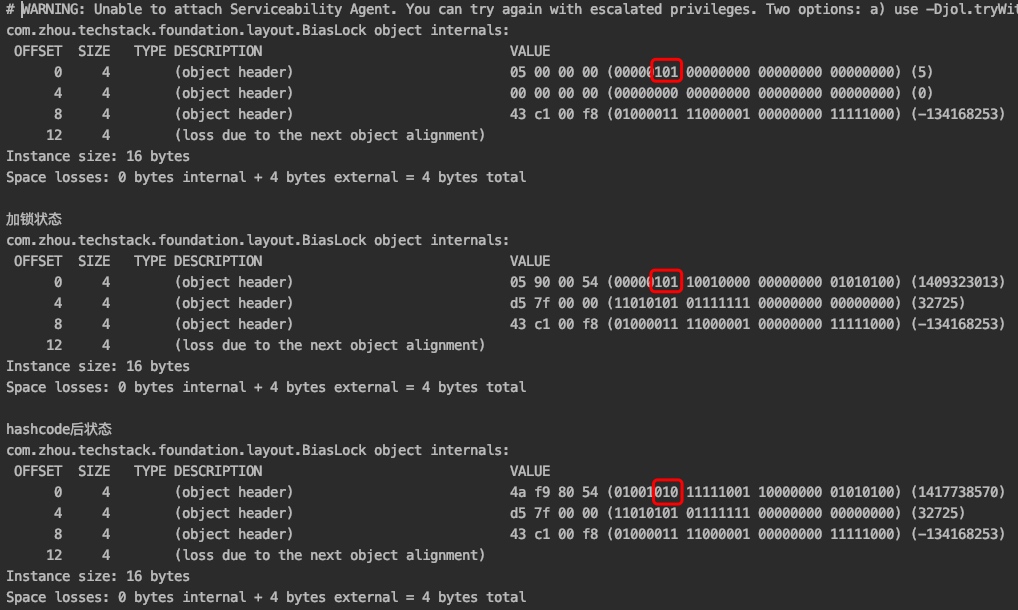
我们关注一下圈出来的部分
大多数cpu使用的是小端序,数据的高位字节存放在地址的高端 低位字节存放在地址低端。锁标志位在对象头中处于最右边的高字节,所以在小端序中就会放到地址的高端,也就是最左边。
- 锁对象初始的时候是匿名偏向状态,
- 加锁之后,还是偏向状态,偏向了当前线程
- 调用hashcode之后,就升级到了重量级锁
那么下面我们就根据代码具体分析一下。 hashCode()是本地native方法,实现最终调用是synchronizer.cpp中的ObjectSynchronizer::FastHashCode
intptr_t ObjectSynchronizer::FastHashCode(Thread * Self, oop obj) {
//首先就判断了JVM是否启用了偏向锁(这个由参数配置),
if (UseBiasedLocking) {
// NOTE: many places throughout the JVM do not expect a safepoint
// to be taken here, in particular most operations on perm gen
// objects. However, we only ever bias Java instances and all of
// the call sites of identity_hash that might revoke biases have
// been checked to make sure they can handle a safepoint. The
// added check of the bias pattern is to avoid useless calls to
// thread-local storage.
if (obj->mark()->has_bias_pattern()) {
// Handle for oop obj in case of STW safepoint
Handle hobj(Self, obj);
//然后判断当前是否是偏向模式(即偏向还没有被撤销),
//如果都是,则撤销偏向模式
BiasedLocking::revoke_and_rebias(hobj, false, JavaThread::current());
obj = hobj();
}
}
ObjectMonitor* monitor = NULL;
markOop temp, test;
intptr_t hash;
markOop mark = ReadStableMark(obj);
//无锁状态
//当在同步方法执行之前,调用hashcode,那么会进入这里
if (mark->is_neutral()) {
//这里会先去对象头中拿hash
hash = mark->hash(); // this is a normal header
if (hash) { // if it has hash, just return it
return hash;
}
//如果为空,则重新计算hash,并设置到一个对象头中
hash = get_next_hash(Self, obj); // allocate a new hash code
temp = mark->copy_set_hash(hash); // merge the hash code into header
// use (machine word version) atomic operation to install the hash
// 如果设置成功则返回计算的hashcode
test = (markOop) Atomic::cmpxchg_ptr(temp, obj->mark_addr(), mark);
if (test == mark) {
return hash;
}
// If atomic operation failed, we must inflate the header
// into heavy weight monitor. We could add more code here
// for fast path, but it does not worth the complexity.
//这种是重量级锁的情况下,尝试从monitor中保存的对象头中获取hashcode,如果获取不到则升级到重量级锁
} else if (mark->has_monitor()) {
monitor = mark->monitor();
temp = monitor->header();
assert(temp->is_neutral(), "invariant");
hash = temp->hash();
if (hash) {
return hash;
}
// Skip to the following code to reduce code size
//如果是轻量级锁,尝试再对象头中获取,如果获取不到则升级到重量级锁
} else if (Self->is_lock_owned((address)mark->locker())) {
temp = mark->displaced_mark_helper(); // this is a lightweight monitor owned
assert(temp->is_neutral(), "invariant");
hash = temp->hash(); // by current thread, check if the displaced
if (hash) { // header contains hash code
return hash;
}
// WARNING:
// The displaced header is strictly immutable.
// It can NOT be changed in ANY cases. So we have
// to inflate the header into heavyweight monitor
// even the current thread owns the lock. The reason
// is the BasicLock (stack slot) will be asynchronously
// read by other threads during the inflate() function.
// Any change to stack may not propagate to other threads
// correctly.
}
// Inflate the monitor to set hash code
// 到这儿,说明没有获取到hashCode,首先直接将锁膨胀为轻量级锁,然后获取hashcode并且设置hsahcode
monitor = ObjectSynchronizer::inflate(Self, obj);
// Load displaced header and check it has hash code
mark = monitor->header();
assert(mark->is_neutral(), "invariant");
hash = mark->hash();
if (hash == 0) {
hash = get_next_hash(Self, obj);
temp = mark->copy_set_hash(hash); // merge hash code into header
assert(temp->is_neutral(), "invariant");
test = (markOop) Atomic::cmpxchg_ptr(temp, monitor, mark);
if (test != mark) {
// The only update to the header in the monitor (outside GC)
// is install the hash code. If someone add new usage of
// displaced header, please update this code
hash = test->hash();
assert(test->is_neutral(), "invariant");
assert(hash != 0, "Trivial unexpected object/monitor header usage.");
}
}
// We finally get the hash
return hash;我们来分析一下执行流程。
- 如果JVM开启了偏向锁,并且锁处于偏向模式,就会调用
revoke_and_rebias撤销偏向 - 如果锁对象处于无锁状态,就会计算hashcode,并设置到对象头中,如果设置成功,返回计算的hashcode
- 如果锁是处于重量级锁状态,就从Monitor中的保存的对象头中获取hashcode
- 如果处于轻量级,就从Lock Record保存的对象头中获取hashcode
- 如果上述操作失败了,或者没有获取到,则会把锁升级到重量级,然后重新计算并返回。
所以就能解释上面Java代码的情况了
- 执行hashcode()时,锁处于偏向状态,所以首先会执行
revoke_and_bias,撤销偏向锁,然后进入revoke_bias,判断当前线程还存活,所以会升级到轻量级锁。 - 继续回到hashcode中执行,就会走到轻量级的判断,因为这时候还没所有生成过hashcode,所以Lock Record中的hashcode是空的,所以就会继续向下走升级到重量级锁。
关于偏向撤销的思考
其实这里我也一直有一个疑问,就是在很多情况下,直接重偏向应该是一个更好的选择,那为什么每次都要先进行偏向撤销?
我自己考虑可能会有两个方面的原因
- 首先重偏向的操作不能影响正在持有锁的线程。因为单单只根据对象头无法得知持有偏向锁线程的状态。所以正常的偏向只能发生在从匿名偏向到偏向的这个过程。而重偏向也只有在安全点中,也就是能够确认线程已经执行完同步代码的情况下才能发生(也就是 revoke_bias中最下面的那段逻辑)
- 另一个原因就是,既然会有锁升级,那就表示每个阶段的锁都有最适合自己的场景。既然已经有了多个线程尝试获取锁,那么就说明在一定程度上已经到了不适合偏向锁的场景了,如果强行使用偏向锁,那么就会无法利用到偏向锁的优势,反而造成锁性能下降。
偏向锁的优势就在于少了一次CAS操作,偏向锁在偏向之后,如果是同一个线程尝试加锁,只需要一次比较操作,就能加锁成功。 如果强行使用偏向锁,当一个线程尝试锁定一个已经偏向另一个线程的锁对象的时候,直接进行重偏向,那么这时候需要进行的操作就是
- 判断是不是偏向状态
- 判断是不是偏向的线程
- 还得等到安全点判断之前的线程是否还存活(这个是最要命的)
- CAS替换偏向线程ID 这样的话,就损失掉了偏向锁相对于轻量级锁的优势。而且多耗费了很多
所以JVM在遇到有多个线程尝试锁定同一个对象的时候,会直接锁升级。 所以有就有说到了上面的提到的不同锁,使用场景问题。 让偏向锁只工作在自己最优的没有线程竞争的环境下,从而达到最佳的性能。
轻量级锁过程
轻量级锁被设计用于多个线程交替访问场景下的synchronized,适用一次CAS就能获取到锁。
轻量级获取
当上面的偏向锁获取失败的时候,会升级到轻量级锁。 这时候锁对象的对象头格式也会发生相应的变化,在锁对象的对象头中,会存储一个指向持有锁的线程的线程栈中的一个Lock Record的指针。 被Lock Record指针锁顶替的对象头中其他字段的信息,为在Lock Record中存储。
CASE(_monitorenter): {
oop lockee = STACK_OBJECT(-1);
...
if (entry != NULL) {
...
// 上面省略的代码中如果CAS操作失败也会调用到InterpreterRuntime::monitorenter
// traditional lightweight locking
//轻量级锁
if (!success) {
//设置当前的对象头为无锁状态,并且复制到Lock Record中的markoop中
markOop displaced = lockee->mark()->set_unlocked();
entry->lock()->set_displaced_header(displaced);
bool call_vm = UseHeavyMonitors;
//将对象头中的地址替换为指向Lock Record的指针,替换成功,则说明获取轻量级锁成功,则什么都不做。
//这里替换失败有两种情况
// 1.发生了竞争
// 2.是锁重入
//所以下面继续判断是否为所重入
if (call_vm || Atomic::cmpxchg_ptr(entry, lockee->mark_addr(), displaced) != displaced) {
// Is it simple recursive case?
//这里判断是不是锁重入,判断指向Lock Record的指针指向的地址是否属于当前线程栈
if (!call_vm && THREAD->is_lock_owned((address) displaced->clear_lock_bits())) {
//如果是轻量级锁的锁重入,说明前面set_displaced_header设置的是第一个Lock Record的地址,
//所以要重新将申请的Lock Record的displaced_header置为空,同样也会通过申请的displaced_header的个数来统计轻量级锁的重入次数
//栈的最高位的Lock Record的displaced_header不是空,重入锁退出锁的时候,会由低到高遍历退出,只在最后一个锁的时候使用CAS替换
entry->lock()->set_displaced_header(NULL);
} else {
//不是所重入,是发生了竞争,则进行锁升级
CALL_VM(InterpreterRuntime::monitorenter(THREAD, entry), handle_exception);
}
}
} UPDATE_PC_AND_TOS_AND_CONTINUE(1, -1);
} else {
istate->set_msg(more_monitors);
UPDATE_PC_AND_RETURN(0); // Re-execute
}
}- 构建一个无锁状态的对象头,(也就是把对象头的后三位设置为001,其他位不变)
- 把这个无锁的对象头保存到Lock Record中的Displaced header中。
- 判断是否有UseHeavyMonitors参数,如果有,则直接走重量级锁
- 使用CAS操作,把指向当前Lock Record的对象头,替换到锁对象的对象头中。
- 如果CAS成功,则表示获取成功,则结束
- 如果CAS失败,则表示当前锁对象的对象头已经不是无锁状态,已经有线程轻量级锁定了这个对象
- 需要判断是不是当前线程,如果是当前线程则表示是重入
- 如果不是当前线程,则表示发生了线程争抢,另一个线程已经获取到了轻量级锁,则需要进行锁升级
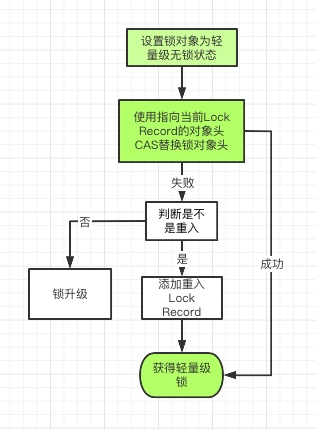
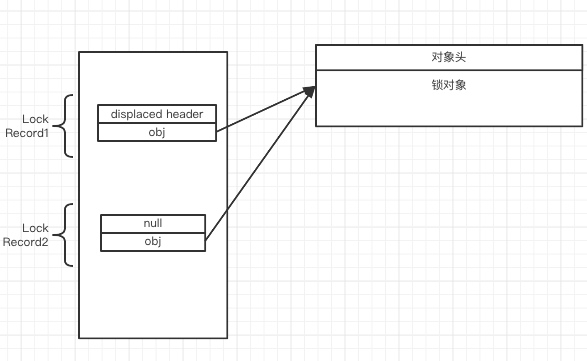
轻量级锁重入处理
当发生了,轻量级锁重入,会把第二次重入的displaced header 设置为null,因为记录重入后的对象头是没有必要的,因为所有的重入锁都退出之后,最终还是要把最开始的那个lock record中的displaced header还原到锁对象头中。中间的重入操作都可能省略掉这个操作。
轻量级释放
CASE(_monitorexit): {
oop lockee = STACK_OBJECT(-1);
CHECK_NULL(lockee);
// derefing's lockee ought to provoke implicit null check
// find our monitor slot
BasicObjectLock* limit = istate->monitor_base();
BasicObjectLock* most_recent = (BasicObjectLock*) istate->stack_base();
//循环遍历线程栈中的Lock Record
while (most_recent != limit ) {
//如果Lock Record的Obj指向的是当前锁对象,说明是当前锁对象的Lock Record
if ((most_recent)->obj() == lockee) {
BasicLock* lock = most_recent->lock();
markOop header = lock->displaced_header();
//将obj设置为Null
most_recent->set_obj(NULL);
//如果不是偏向模式(即是轻量级锁)
if (!lockee->mark()->has_bias_pattern()) {
bool call_vm = UseHeavyMonitors;
// If it isn't recursive we either must swap old header or call the runtime
if (header != NULL || call_vm) {
//将对象头中的markoop替换为Lock Record中的markoop
if (call_vm || Atomic::cmpxchg_ptr(header, lockee->mark_addr(), lock) != lock) {
// restore object for the slow case
//如果替换失败,则还原Lock Record,并且执行锁升级的monitorexit
//说明在持有轻量级锁期间,有另一个线程,尝试获取,导致锁已经升级到重量级了
most_recent->set_obj(lockee);
CALL_VM(InterpreterRuntime::monitorexit(THREAD, most_recent), handle_exception);
}
}
}
UPDATE_PC_AND_TOS_AND_CONTINUE(1, -1);
}
most_recent++;
}
// Need to throw illegal monitor state exception
CALL_VM(InterpreterRuntime::throw_illegal_monitor_state_exception(THREAD), handle_exception);
ShouldNotReachHere();
}- 循环遍历当前线程的线程栈,找到指向当前锁对象的Lock Record.
- 将Lock Record的obj设置为空,也就是不再让Lock Record指向锁对象。(这个动作偏向锁也会有)
- 判断如果是轻量级锁,然后判断如果Lock Record的Displaced header不为空,则通过CAS将Displaced header中的markoop替换回对象头中。前面讲轻量级锁获取的时候也有提到过,如果是轻量级锁重入,则Lock Record的Displaced header设置为空,这里退出的时候,会判断如果不为空则替换。
如果替换成功,则释放锁成功。如果替换失败,则说明当前锁被其他线程抢占过,所已经升级到了重量级。所以要执行InterpreterRuntime::monitorexit的退出逻辑,monitorexit中,主要做的是轻量级锁的退出和锁膨胀为重量级锁。
IRT_ENTRY_NO_ASYNC(void, InterpreterRuntime::monitorexit(JavaThread* thread, BasicObjectLock* elem)) #ifdef ASSERT thread->last_frame().interpreter_frame_verify_monitor(elem); #endif Handle h_obj(thread, elem->obj()); assert(Universe::heap()->is_in_reserved_or_null(h_obj()), "must be NULL or an object"); if (elem == NULL || h_obj()->is_unlocked()) { THROW(vmSymbols::java_lang_IllegalMonitorStateException()); } ObjectSynchronizer::slow_exit(h_obj(), elem->lock(), thread); // Free entry. This must be done here, since a pending exception might be installed on // exit. If it is not cleared, the exception handling code will try to unlock the monitor again. elem->set_obj(NULL); #ifdef ASSERT thread->last_frame().interpreter_frame_verify_monitor(elem); #endif IRT_ENDvoid ObjectSynchronizer::fast_exit(oop object, BasicLock* lock, TRAPS) { assert(!object->mark()->has_bias_pattern(), "should not see bias pattern here"); // if displaced header is null, the previous enter is recursive enter, no-op markOop dhw = lock->displaced_header(); markOop mark; //这里判断,Lock Record的displaced_header是否为空,如果是,当前的Lock Record是重入中的一个。 //如果没有持有轻量级锁,那就没必要执行膨胀了,直接返回。中间assert了一下是否已经是重量级锁,别的什么也没做。 if (dhw == NULL) { // Recursive stack-lock. // Diagnostics -- Could be: stack-locked, inflating, inflated. mark = object->mark(); assert(!mark->is_neutral(), "invariant"); if (mark->has_locker() && mark != markOopDesc::INFLATING()) { assert(THREAD->is_lock_owned((address)mark->locker()), "invariant"); } if (mark->has_monitor()) { ObjectMonitor * m = mark->monitor(); assert(((oop)(m->object()))->mark() == mark, "invariant"); assert(m->is_entered(THREAD), "invariant"); } return; } //执行到这儿,说明Lock Record的displaced_header不为空,说明可能是轻量级锁,也可能已经膨胀为了重量级锁。 mark = object->mark(); // If the object is stack-locked by the current thread, try to // swing the displaced header from the box back to the mark. //尝试将其强转为markOop,成功,则说明还是轻量级锁,则尝试用CAS将Lock Record的isplaced_header替换回对象头。 //则尝试释放轻量级锁,即通过CAS将displaced header替换回对象头中,替换成功则说明轻量级锁释放成功。 if (mark == (markOop) lock) { assert(dhw->is_neutral(), "invariant"); if ((markOop) Atomic::cmpxchg_ptr (dhw, object->mark_addr(), mark) == mark) { TEVENT(fast_exit: release stacklock); return; } } //开始执行锁的膨胀升级为重量级锁,并且执行exit ObjectSynchronizer::inflate(THREAD, object)->exit(true, THREAD); }这里判断,Lock Record的displaced_header是否为空,如果是,则说明已经没有持有当前轻量级级锁了。如果没有持有轻量级锁,那就没必要执行膨胀了,直接返回。中间assert了一下是否已经是重量级锁,别的什么也没做。
如果Lock Record的displaced_header不为空, 判断如果当前对象头还是轻量级锁,并且指向的是当前Lock Record,则尝试释放轻量级锁,即通过CAS将displaced header替换回对象头中,替换成功则说明轻量级锁释放成功。
如果前面的判断或者是替换都失败了,就开始执行ObjectSynchronizer::inflate进行锁膨胀为重量级锁。膨胀成功后ObjectSynchronizer::inflate的返回值为ObjectMonitor对象,ObjectMonitor就是用于实现重量级锁的。然后调用ObjectMonitor的exit方法进行锁的释放。
重量级锁
重量级锁被设计用于有线程竞争的场景的,在重量级模式下,没有获取到锁的线程,会先通过自旋,然后进入阻塞操作。避免大量无效的自旋,占用过多的CPU资源。 下面我们还是通过代码来分析一下。
重量级锁获取
在偏向锁撤销之后,会调用到slow_enter方法,然后在进行一次轻量级获取,如果仍然失败,就会执行inflate,锁膨胀,并返回一下ObjectMonitor对象。
void ObjectSynchronizer::slow_enter(Handle obj, BasicLock* lock, TRAPS) {
markOop mark = obj->mark();
assert(!mark->has_bias_pattern(), "should not see bias pattern here");
//无锁状态
if (mark->is_neutral()) {
// Anticipate successful CAS -- the ST of the displaced mark must
// be visible <= the ST performed by the CAS.
lock->set_displaced_header(mark);
if (mark == (markOop) Atomic::cmpxchg_ptr(lock, obj()->mark_addr(), mark)) {
TEVENT(slow_enter: release stacklock);
return;
}
// Fall through to inflate() ...
// 轻量级锁重入
} else if (mark->has_locker() &&
THREAD->is_lock_owned((address)mark->locker())) {
assert(lock != mark->locker(), "must not re-lock the same lock");
assert(lock != (BasicLock*)obj->mark(), "don't relock with same BasicLock");
lock->set_displaced_header(NULL);
return;
}
// The object header will never be displaced to this lock,
// so it does not matter what the value is, except that it
// must be non-zero to avoid looking like a re-entrant lock,
// and must not look locked either.
// 现在这个lock是没有获取到锁的线程的lock record,现在存储的是什么并不重要,所以设置没有什么特殊意义的值。
// 不能为null,因为null代表重入
// 不能为0,10,01,因为他们都有相对的意义,所以只能为11了
lock->set_displaced_header(markOopDesc::unused_mark());
//开始升级为重量级锁
ObjectSynchronizer::inflate(THREAD, obj())->enter(THREAD);
}获取monitor对象 inflate
ObjectMonitor * NOINLINE ObjectSynchronizer::inflate(Thread * Self,
oop object) {
// Inflate mutates the heap ...
// Relaxing assertion for bug 6320749.
assert(Universe::verify_in_progress() ||
!SafepointSynchronize::is_at_safepoint(), "invariant");
for (;;) {
//获取锁对象的markoop
const markOop mark = object->mark();
assert(!mark->has_bias_pattern(), "invariant");
// The mark can be in one of the following states:
// * Inflated - just return
// * Stack-locked - coerce it to inflated
// * INFLATING - busy wait for conversion to complete
// * Neutral - aggressively inflate the object.
// * BIASED - Illegal. We should never see this
// CASE: inflated
//判断是否有Objectmonitor,如果有,说明已经膨胀过了,直接返回monitor
if (mark->has_monitor()) {
ObjectMonitor * inf = mark->monitor();
assert(inf->header()->is_neutral(), "invariant");
assert(inf->object() == object, "invariant");
assert(ObjectSynchronizer::verify_objmon_isinpool(inf), "monitor is invalid");
return inf;
}
// CASE: inflation in progress - inflating over a stack-lock.
// Some other thread is converting from stack-locked to inflated.
// Only that thread can complete inflation -- other threads must wait.
// The INFLATING value is transient.
// Currently, we spin/yield/park and poll the markword, waiting for inflation to finish.
// We could always eliminate polling by parking the thread on some auxiliary list.
//如果有其他线程正在执行膨胀,则当前线程不再去执行膨胀逻辑,进行忙等待,直到膨胀完成
if (mark == markOopDesc::INFLATING()) {
TEVENT(Inflate: spin while INFLATING);
ReadStableMark(object);
continue;
}
// CASE: stack-locked
// Could be stack-locked either by this thread or by some other thread.
//
// Note that we allocate the objectmonitor speculatively, _before_ attempting
// to install INFLATING into the mark word. We originally installed INFLATING,
// allocated the objectmonitor, and then finally STed the address of the
// objectmonitor into the mark. This was correct, but artificially lengthened
// the interval in which INFLATED appeared in the mark, thus increasing
// the odds of inflation contention.
//
// We now use per-thread private objectmonitor free lists.
// These list are reprovisioned from the global free list outside the
// critical INFLATING...ST interval. A thread can transfer
// multiple objectmonitors en-mass from the global free list to its local free list.
// This reduces coherency traffic and lock contention on the global free list.
// Using such local free lists, it doesn't matter if the omAlloc() call appears
// before or after the CAS(INFLATING) operation.
// See the comments in omAlloc().
//判断目前对象头的状态是否是轻量级锁的状态,则创建一个ObjectMonitor并进行初始化
if (mark->has_locker()) {
//创建一个ObjectMonitor
//omAlloc(Self)会尝试优先从tlab里面分配
ObjectMonitor * m = omAlloc(Self);
// Optimistically prepare the objectmonitor - anticipate successful CAS
// We do this before the CAS in order to minimize the length of time
// in which INFLATING appears in the mark.
m->Recycle();
m->_Responsible = NULL;
m->_recursions = 0;
m->_SpinDuration = ObjectMonitor::Knob_SpinLimit; // Consider: maintain by type/class
//设置对象的状态为膨胀中,设置失败则重新执行膨胀逻辑
//如果设置失败,则表示已经有线程膨胀完成了,所以continue,在进行上面是否有monitor的判断,然后膨胀完的monitor
markOop cmp = (markOop) Atomic::cmpxchg_ptr(markOopDesc::INFLATING(), object->mark_addr(), mark);
if (cmp != mark) {
omRelease(Self, m, true);
continue; // Interference -- just retry
}
//这里描述了为什么需要添加一个 INFLATING状态
// We've successfully installed INFLATING (0) into the mark-word.
// This is the only case where 0 will appear in a mark-word.
// Only the singular thread that successfully swings the mark-word
// to 0 can perform (or more precisely, complete) inflation.
//
// Why do we CAS a 0 into the mark-word instead of just CASing the
// mark-word from the stack-locked value directly to the new inflated state?
// Consider what happens when a thread unlocks a stack-locked object.
// It attempts to use CAS to swing the displaced header value from the
// on-stack basiclock back into the object header. Recall also that the
// header value (hashcode, etc) can reside in (a) the object header, or
// (b) a displaced header associated with the stack-lock, or (c) a displaced
// header in an objectMonitor. The inflate() routine must copy the header
// value from the basiclock on the owner's stack to the objectMonitor, all
// the while preserving the hashCode stability invariants. If the owner
// decides to release the lock while the value is 0, the unlock will fail
// and control will eventually pass from slow_exit() to inflate. The owner
// will then spin, waiting for the 0 value to disappear. Put another way,
// the 0 causes the owner to stall if the owner happens to try to
// drop the lock (restoring the header from the basiclock to the object)
// while inflation is in-progress. This protocol avoids races that might
// would otherwise permit hashCode values to change or "flicker" for an object.
// Critically, while object->mark is 0 mark->displaced_mark_helper() is stable.
// 0 serves as a "BUSY" inflate-in-progress indicator.
// fetch the displaced mark from the owner's stack.
// The owner can't die or unwind past the lock while our INFLATING
// object is in the mark. Furthermore the owner can't complete
// an unlock on the object, either.
markOop dmw = mark->displaced_mark_helper();
assert(dmw->is_neutral(), "invariant");
// Setup monitor fields to proper values -- prepare the monitor
// 吧当前的锁对象头,保存到monitor中
m->set_header(dmw);
// Optimization: if the mark->locker stack address is associated
// with this thread we could simply set m->_owner = Self.
// Note that a thread can inflate an object
// that it has stack-locked -- as might happen in wait() -- directly
// with CAS. That is, we can avoid the xchg-NULL .... ST idiom.
//关键哈,把重量级Monitor的持有这,设置为当前整持有这个轻量级锁的线程的 Lock Record地址
m->set_owner(mark->locker());
m->set_object(object);
// TODO-FIXME: assert BasicLock->dhw != 0.
// Must preserve store ordering. The monitor state must
// be stable at the time of publishing the monitor address.
guarantee(object->mark() == markOopDesc::INFLATING(), "invariant");
//设置对象头指向当前的objectmonitor
object->release_set_mark(markOopDesc::encode(m));
return m;
}
// CASE: neutral
// TODO-FIXME: for entry we currently inflate and then try to CAS _owner.
// If we know we're inflating for entry it's better to inflate by swinging a
// pre-locked objectMonitor pointer into the object header. A successful
// CAS inflates the object *and* confers ownership to the inflating thread.
// In the current implementation we use a 2-step mechanism where we CAS()
// to inflate and then CAS() again to try to swing _owner from NULL to Self.
// An inflateTry() method that we could call from fast_enter() and slow_enter()
// would be useful.
assert(mark->is_neutral(), "invariant");
//创建ObjectMonitor
ObjectMonitor * m = omAlloc(Self);
// prepare m for installation - set monitor to initial state
m->Recycle();
m->set_header(mark);
m->set_owner(NULL);
m->set_object(object);
m->_recursions = 0;
m->_Responsible = NULL;
m->_SpinDuration = ObjectMonitor::Knob_SpinLimit; // consider: keep metastats by type/class
//把对象头替换为执行objectMonitor的指针
if (Atomic::cmpxchg_ptr (markOopDesc::encode(m), object->mark_addr(), mark) != mark) {
m->set_object(NULL);
m->set_owner(NULL);
m->Recycle();
omRelease(Self, m, true);
m = NULL;
continue;
// interference - the markword changed - just retry.
// The state-transitions are one-way, so there's no chance of
// live-lock -- "Inflated" is an absorbing state.
}
// Hopefully the performance counters are allocated on distinct
// cache lines to avoid false sharing on MP systems ...
OM_PERFDATA_OP(Inflations, inc());
TEVENT(Inflate: overwrite neutral);
if (log_is_enabled(Debug, monitorinflation)) {
if (object->is_instance()) {
ResourceMark rm;
log_debug(monitorinflation)("Inflating object " INTPTR_FORMAT " , mark " INTPTR_FORMAT " , type %s",
p2i(object), p2i(object->mark()),
object->klass()->external_name());
}
}
return m;
}
}inflate方法的功能是返回一个可用ObjectMonitor对象,如果没有就创建一个。inflate中是一个for循环,主要是为了处理多线程同时调用inflate的情况。然后会根据锁对象的状态进行不同的处理:
- 已经是重量级状态,说明膨胀已经完成已经有了ObjectMonitor,直接返回
- 如果是轻量级锁则需要进行膨胀操作
- 如果是膨胀中状态,则进行忙等待
- 如果是无锁状态则需要进行膨胀操作
其中轻量级锁和无锁状态需要进行膨胀操作,轻量级锁膨胀流程如下:
- 调用omAlloc分配一个ObjectMonitor对象(以下简称monitor),在omAlloc方法中会先从线程私有的monitor集合omFreeList中分配对象,如果omFreeList中已经没有monitor对象,则从JVM全局的gFreeList中分配一批monitor到omFreeList中。
- 初始化monitor对象
- 将状态设置为膨胀中(INFLATING)状态
- 设置monitor的header字段为displaced mark word,obj字段为锁对象
- 设置owner字段为之前持有轻量级锁的线程的Lock Record,也就是膨胀完之后,要让之前持有锁的线程继续持有这个重量级锁,谁能用自己的Lock Record设置owner,就表示谁获取到了这个重量级锁
- 设置锁对象头的mark word为重量级锁状态,指向第一步分配的monitor对象
无锁状态下的膨胀流程如下:
- 调用omAlloc分配一个ObjectMonitor对象(以下简称monitor)
- 初始化monitor对象
- 设置monitor的header字段为 mark word,owner字段为null,obj字段为锁对象
- 设置锁对象头的mark word为重量级锁状态,指向第一步分配的monitor对象
进入重量级锁 enter
在获得了Monitor之后,线程就要进入Monitor,看看能不能获取到重量锁了
void ATTR ObjectMonitor::enter(TRAPS) {
Thread * const Self = THREAD ;
void * cur ;
// owner为null代表无锁状态,如果能CAS设置成功,则当前线程直接获得锁
cur = Atomic::cmpxchg_ptr (Self, &_owner, NULL) ;
if (cur == NULL) {
...
return ;
}
// 如果是重入的情况,则把重入计数器加1
if (cur == Self) {
// TODO-FIXME: check for integer overflow! BUGID 6557169.
_recursions ++ ;
return ;
}
// 当前线程是之前持有轻量级锁的线程。由轻量级锁膨胀且第一次调用enter方法,那cur是指向Lock Record的指针
// 这里也就是说,之前持有轻量级锁的线程,自己膨胀到重量级锁,同志们有印象是什么操作吗,就是在同步代码块中调用了hashcode呀,就会执行到这个逻辑
if (Self->is_lock_owned ((address)cur)) {
assert (_recursions == 0, "internal state error");
// 重入计数重置为1
// 因为之前就是这个线程持有轻量级锁,现在还是这个线程持有重量级锁,还是相当于锁重入了,所以_recursions设置为1,表示重入1次。
_recursions = 1 ;
// 设置owner字段为当前线程(之前owner是指向Lock Record的指针)
_owner = Self ;
return ;
}
...
// 在调用昂贵的系统同步操作之前,先尝试一轮自适应自旋
if (Knob_SpinEarly && TrySpin (Self) > 0) {
...
//自旋的过程中获得了锁,则直接返回
Self->_Stalled = 0 ;
return ;
}
...
{
...
for (;;) {
jt->set_suspend_equivalent();
// 在该方法中调用系统同步操作
EnterI (THREAD) ;
...
}
Self->set_current_pending_monitor(NULL);
}
...
}我们看到,这个enter方法,还是通过CAS和自旋来尝试获得重量级锁,如果同构这两步能够获取成功,那么就能够避免切换到内核态去执行。 如果不能获取到,也不能让线程一直自旋获取,需要调用EnterI来获取锁,获取进入阻塞状态。
重量级进入 EnterI
在进入到这个方法之前,我们在来熟悉一下ObjectMonitor中比较重要的属性,有的之前已经见到了,有的还没有
| 名称 | 作用 |
|---|---|
| _header | 保存锁对象的对象头markoop |
| _object | 锁对象 |
| _owner | 正常情况下是持有锁的线程,如果是有轻量级膨胀上来的,那么会是当时轻量级Lock Reord |
| _recursions | 重量级锁的重入次数 |
| _EntryList | 被阻塞的线程重新进入时,会将其放在当前队列中。其实这个队列是被wait()方法阻塞的线程,当调用notify/notifyAll时,会将准备唤醒的线程放在这个队列中。 |
| _cxq | 当对象锁已经被一个线程持有,其他所有的线程在尝试获取锁的时候,如果没有获取到,将其挂起后都会被放在这个队列上。 |
| _WaitSet | 调用wait()方法阻塞的线程,都会放在当前队列中 |
| _succ | 线程是在线程释放锁是被设置,其含义是Heir presumptive,也就是假定继承人 |
| _Responsible | 当竞争发生时,选取一个线程作为_Responsible,_Responsible线程调用的是有时间限制的park方法,其目的是防止出现搁浅现象。 |
void NOINLINE ObjectMonitor::EnterI(TRAPS) {
Thread * const Self = THREAD;
assert(Self->is_Java_thread(), "invariant");
assert(((JavaThread *) Self)->thread_state() == _thread_blocked, "invariant");
// Try the lock - TATAS
if (TryLock (Self) > 0) {
assert(_succ != Self, "invariant");
assert(_owner == Self, "invariant");
assert(_Responsible != Self, "invariant");
return;
}
DeferredInitialize();
// We try one round of spinning *before* enqueueing Self.
//
// If the _owner is ready but OFFPROC we could use a YieldTo()
// operation to donate the remainder of this thread's quantum
// to the owner. This has subtle but beneficial affinity
// effects.
// 再尝试一轮自旋
// 我们看到这里又同样的逻辑执行了2次,为什么这样呢,
if (TrySpin (Self) > 0) {
assert(_owner == Self, "invariant");
assert(_succ != Self, "invariant");
assert(_Responsible != Self, "invariant");
return;
}
// The Spin failed -- Enqueue and park the thread ...
assert(_succ != Self, "invariant");
assert(_owner != Self, "invariant");
assert(_Responsible != Self, "invariant");
// Enqueue "Self" on ObjectMonitor's _cxq.
//
// Node acts as a proxy for Self.
// As an aside, if were to ever rewrite the synchronization code mostly
// in Java, WaitNodes, ObjectMonitors, and Events would become 1st-class
// Java objects. This would avoid awkward lifecycle and liveness issues,
// as well as eliminate a subset of ABA issues.
// TODO: eliminate ObjectWaiter and enqueue either Threads or Events.
ObjectWaiter node(Self);
Self->_ParkEvent->reset();
node._prev = (ObjectWaiter *) 0xBAD;
node.TState = ObjectWaiter::TS_CXQ;
// Push "Self" onto the front of the _cxq.
// Once on cxq/EntryList, Self stays on-queue until it acquires the lock.
// Note that spinning tends to reduce the rate at which threads
// enqueue and dequeue on EntryList|cxq.
ObjectWaiter * nxt;
for (;;) {
node._next = nxt = _cxq;
//尝试将当前线程放在cxq队列的头部,如果放成功了则跳出循环
if (Atomic::cmpxchg_ptr(&node, &_cxq, nxt) == nxt) break;
// Interference - the CAS failed because _cxq changed. Just retry.
// As an optional optimization we retry the lock.
//放失败了,则说明cxq对象被改变了,则尝试获取锁。
//获取成功则直接返回,获取失败,在继续尝试将线程放在Cxq队列的头部
if (TryLock (Self) > 0) {
assert(_succ != Self, "invariant");
assert(_owner == Self, "invariant");
assert(_Responsible != Self, "invariant");
return;
}
}
// Check for cxq|EntryList edge transition to non-null. This indicates
// the onset of contention. While contention persists exiting threads
// will use a ST:MEMBAR:LD 1-1 exit protocol. When contention abates exit
// operations revert to the faster 1-0 mode. This enter operation may interleave
// (race) a concurrent 1-0 exit operation, resulting in stranding, so we
// arrange for one of the contending thread to use a timed park() operations
// to detect and recover from the race. (Stranding is form of progress failure
// where the monitor is unlocked but all the contending threads remain parked).
// That is, at least one of the contended threads will periodically poll _owner.
// One of the contending threads will become the designated "Responsible" thread.
// The Responsible thread uses a timed park instead of a normal indefinite park
// operation -- it periodically wakes and checks for and recovers from potential
// strandings admitted by 1-0 exit operations. We need at most one Responsible
// thread per-monitor at any given moment. Only threads on cxq|EntryList may
// be responsible for a monitor.
//
// Currently, one of the contended threads takes on the added role of "Responsible".
// A viable alternative would be to use a dedicated "stranding checker" thread
// that periodically iterated over all the threads (or active monitors) and unparked
// successors where there was risk of stranding. This would help eliminate the
// timer scalability issues we see on some platforms as we'd only have one thread
// -- the checker -- parked on a timer.
//这里判断的是,如果nex==null(说明cxq队列为空),并且entryList为空。
//那说明当前线程是第一个阻塞或者等待当前锁的线程
//也就是说,这个线程是进入monitor的第一个线程,那么就把这个线程设置为_Responsible
if ((SyncFlags & 16) == 0 && nxt == NULL && _EntryList == NULL) {
// Try to assume the role of responsible thread for the monitor.
// CONSIDER: ST vs CAS vs { if (Responsible==null) Responsible=Self }
//通过cas将_Responsible指针指向Self
Atomic::cmpxchg_ptr(Self, &_Responsible, NULL);
}
// The lock might have been released while this thread was occupied queueing
// itself onto _cxq. To close the race and avoid "stranding" and
// progress-liveness failure we must resample-retry _owner before parking.
// Note the Dekker/Lamport duality: ST cxq; MEMBAR; LD Owner.
// In this case the ST-MEMBAR is accomplished with CAS().
//
// TODO: Defer all thread state transitions until park-time.
// Since state transitions are heavy and inefficient we'd like
// to defer the state transitions until absolutely necessary,
// and in doing so avoid some transitions ...
TEVENT(Inflated enter - Contention);
int nWakeups = 0;
int recheckInterval = 1;
//执行到这儿,说明线程已经被成功放在了cxq队列的头部,
//然后下面进入一个循环,只有成功获取到了锁,才能够跳出循环。
for (;;) {
//再次尝试获取锁
if (TryLock(Self) > 0) break;
assert(_owner != Self, "invariant");
//如果_Responsible指针为NULL,则再次尝试让_Responsible指向当前线程
if ((SyncFlags & 2) && _Responsible == NULL) {
Atomic::cmpxchg_ptr(Self, &_Responsible, NULL);
}
// park self
//如果_Responsible成功指向了当前线程,说明当前线程是第一个被阻塞或者等待获取锁的线程。
//则会执行一个简单的退避算法。执行有等待时间的park操作,第一次是1ms
//每次到时间后自己去尝试获取锁,获取失败后继续睡眠,每次睡眠的时间是上一次的8倍。
if (_Responsible == Self || (SyncFlags & 1)) {
TEVENT(Inflated enter - park TIMED);
Self->_ParkEvent->park((jlong) recheckInterval);
// Increase the recheckInterval, but clamp the value.
recheckInterval *= 8;
if (recheckInterval > MAX_RECHECK_INTERVAL) {
recheckInterval = MAX_RECHECK_INTERVAL;
}
} else {
//如果当前线程不是第一个阻塞或者等待锁的线程,则直接park。
TEVENT(Inflated enter - park UNTIMED);
Self->_ParkEvent->park();
}
if (TryLock(Self) > 0) break;
// The lock is still contested.
// Keep a tally of the # of futile wakeups.
// Note that the counter is not protected by a lock or updated by atomics.
// That is by design - we trade "lossy" counters which are exposed to
// races during updates for a lower probe effect.
TEVENT(Inflated enter - Futile wakeup);
// This PerfData object can be used in parallel with a safepoint.
// See the work around in PerfDataManager::destroy().
OM_PERFDATA_OP(FutileWakeups, inc());
++nWakeups;
// Assuming this is not a spurious wakeup we'll normally find _succ == Self.
// We can defer clearing _succ until after the spin completes
// TrySpin() must tolerate being called with _succ == Self.
// Try yet another round of adaptive spinning.
if ((Knob_SpinAfterFutile & 1) && TrySpin(Self) > 0) break;
// We can find that we were unpark()ed and redesignated _succ while
// we were spinning. That's harmless. If we iterate and call park(),
// park() will consume the event and return immediately and we'll
// just spin again. This pattern can repeat, leaving _succ to simply
// spin on a CPU. Enable Knob_ResetEvent to clear pending unparks().
// Alternately, we can sample fired() here, and if set, forgo spinning
// in the next iteration.
if ((Knob_ResetEvent & 1) && Self->_ParkEvent->fired()) {
Self->_ParkEvent->reset();
OrderAccess::fence();
}
if (_succ == Self) _succ = NULL;
// Invariant: after clearing _succ a thread *must* retry _owner before parking.
OrderAccess::fence();
}
//执行到这里,说明当前线程成功获取了锁,所以下面要做的事情,就是要将当前线程从当前锁的阻塞队列上去掉,
// Egress :
// Self has acquired the lock -- Unlink Self from the cxq or EntryList.
// Normally we'll find Self on the EntryList .
// From the perspective of the lock owner (this thread), the
// EntryList is stable and cxq is prepend-only.
// The head of cxq is volatile but the interior is stable.
// In addition, Self.TState is stable.
assert(_owner == Self, "invariant");
assert(object() != NULL, "invariant");
// I'd like to write:
// guarantee (((oop)(object()))->mark() == markOopDesc::encode(this), "invariant") ;
// but as we're at a safepoint that's not safe.
//从队列中去掉当前线程的操作
UnlinkAfterAcquire(Self, &node);
if (_succ == Self) _succ = NULL;
assert(_succ != Self, "invariant");
//如果_Responsible是当前线程,则将_Responsible设置为NULL
if (_Responsible == Self) {
_Responsible = NULL;
OrderAccess::fence(); // Dekker pivot-point
}
return;
}首先还是尝试获取锁,获取失败后再尝试自旋一下,自旋依旧失败,之后是真正的挂起逻辑。 当时这里进行了2轮自旋,尝试自旋获得锁,我们可以理解,是为了尽可能的在用户态获得锁,那为什么要执行2次呢?
// We try one round of spinning *before* enqueueing Self. // // If the _owner is ready but OFFPROC we could use a YieldTo() // operation to donate the remainder of this thread's quantum // to the owner. This has subtle but beneficial affinity // effects.
上面的注释给了我们答案,这么做会有一些微秒的亲和力影响。
什么是亲和力?这是很多操作系统中都有的一种 CPU 执行调度逻辑,说的是,如果在过去一段时间内,某个线程尝试获取某种资源一直失败,那么系统在后面会倾向于将该资源分配给这个线程。这里我们前后两次执行,就是告诉系统当前线程「迫切」想要获得这个 cas 资源,如果可以用的话尽量分配给它。当然这种亲和力不是一种得到保证的协议,因此这种操作只能是一种积极的、并且人畜无害的操作。
执行真正挂起逻辑之前,首先将自己包装成一个ObjectWaiter对象,并通过CAS放在_cxq队列的头部。
执行真正挂起逻辑的时候,有一个指针_Responsible,当cxq队列和_EntryList为空,并且_Responsible为空的时候,说明当前线程是第一个等待锁的线程,就通过CAS将_Responsible指向当前线程。 然后,进入到一个无限循环中,只有成功获取了锁,才能退出循环。
_Responsible的作用是什么呢// Check for cxq|EntryList edge transition to non-null. This indicates // the onset of contention. While contention persists exiting threads // will use a ST:MEMBAR:LD 1-1 exit protocol. When contention abates exit // operations revert to the faster 1-0 mode. This enter operation may interleave // (race) a concurrent 1-0 exit operation, resulting in stranding, so we // arrange for one of the contending thread to use a timed park() operations // to detect and recover from the race. (Stranding is form of progress failure // where the monitor is unlocked but all the contending threads remain parked). // That is, at least one of the contended threads will periodically poll _owner. // One of the contending threads will become the designated "Responsible" thread. // The Responsible thread uses a timed park instead of a normal indefinite park // operation -- it periodically wakes and checks for and recovers from potential // strandings admitted by 1-0 exit operations. We need at most one Responsible // thread per-monitor at any given moment. Only threads on cxq|EntryList may // be responsible for a monitor.上面的注释中说到,重量级操作中,是有可能发生搁浅(搁浅是指:Monitor已解锁但所有竞争线程均已park,就是没有线程去尝试获取锁),为了避免这种情况。需要指定一个线程,定期唤醒去执行执行检查,或者说去尝试获取锁。保证至少有一个线程能够获取锁。
如果_Responsible指向的是当前程,就通过一个简单的退避算法进行有条件的挂起,第一次1ms,第二次8ms,每次下一次都是上一次睡眠时间的8倍,但时间自动唤醒自己并尝试获取锁。
如果_Responsible指向的不是当前线程,则当前线程会执行park将自己挂起,只有当前得到锁的线程释放锁的时候,才有机会被唤醒并且竞争锁。
最后,当获取到锁之后,就会跳出循环,填出循环后需要做一些后续处理,需要把自己从等待队列中移除,
如果如果是
_Responsible线程获取到了了,那么就需要把_Responsible设置为null,等待其他线程被唤醒的使用重新设置为_Responsible。
降到这里其实加锁过程,就差不多完成了,可能会有一些疑惑,为什么 EntryList cxq 这些都没怎么用到呢? 别急在重量级锁退出的时候,就会用到了,我们机械往下分析。
自旋锁和适应性自旋
我们看到在重量级代码中,有很多次的出现了自旋的操作,这么做的目的就是,尽量在用户态解决战斗,防止线程无谓地进行状态切换。所以我们能从中知道,尽量避免无效的状态切换对于一个高性能的系统有多么重要。
但是要想不切换到内核态,就必须要给线程找点事情做,所以就需要线程进行自旋。上面在重量级锁的获取中,看到了很多采用TryLock,来尝试自旋获取锁。这个其实就是我们经常说的自旋锁。
我觉得准确来说自旋不能算作一种锁,在Java里它只能算是一种获取重量级锁的优化方式。在线程占有锁时间比较短的情况下,能够避免其他等待锁线程切换到内核态进入阻塞状态
自旋锁在JDK 1.4.2中就已经引入,只不过默认是关闭的,可以使用-XX:+UseSpinning参数来开启,在JDK 1.6中就已经改为默认开启了。 自旋等待不能代替阻塞,因为自旋等待本身虽然避免了线程切换的开销,但它是要占用处理器时间的,因此,如果锁被占用的时间很短,自旋等待的效果就会非常好,反之,如果锁被占用的时间很长,那么自旋的线程只会白白消耗处理器资源, 而不会做任何有用的工作,反而会带来性能上的浪费。因此,自旋等待的时间必须要有一定的限度,如果自旋超过了限定的次数仍然没有成功获得锁,就应当使用传统的方式去挂起线程了。 自旋次数的默认值是10次,用户可以使用参数-XX:PreBlockSpin来更改。
在JDK 1.6中引入了自适应的自旋锁。自适应意味着自旋的时间不再固定了,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。 如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也很有可能再次成功,进而它将允许自旋等待持续相对更长的时间,比如100个循环。 另外,如果对于某个锁,自旋很少成功获得过,那在以后要获取这个锁时将可能省略掉自旋过程,以避免浪费处理器资源。有了自适应自旋,随着程序运行和性能监控信息的不断完善,虚拟机对程序锁的状况预测就会越来越准确,虚拟机就会变得越来越“聪明”了。
重量级锁释放
上面我们理清了 ObjectMonitor enter 的逻辑,我们知道了如下几件事情:
- ObjectMonitor 内部通过一个 CXQ 队列保存所有的等待线程
- 在实际进入队列之前,会反复尝试 lock,在某些系统上会存在 CPU 亲和力的优化
- 入队的时候,通过 ObjectWaiter 对象将当前线程包裹起来,并且入到 CXQ 队列的头部
- 入队成功以后,会根据当前线程是否为第一个等待线程做不同的处理,如果是第一个这个线程会被设置为
_Responsible。 - 如果是第一个等待线程,会根据一个简单的「退避算法」来有条件的 wait,并定时醒来继续尝试获取
- 如果不是第一个等待线程,那么会执行无限期等待
- 如果
_Responsible线程获取到重量级锁,会将_Responsible设置为null - 线程的 park 在 posix 系统上是通过 pthread 的 condition wait 实现的
当一个线程获得对象锁成功之后,就可以执行自定义的同步代码块了。执行完成之后会执行到 ObjectMonitor 的 exit 函数中,释放当前对象锁,方便下一个线程来获取这个锁,下面我们逐步分析下 exit 的实现过程。
exit 函数的实现比较长,但是整体上的结构比较清晰:
void ATTR ObjectMonitor::exit(bool not_suspended, TRAPS) {
Thread * Self = THREAD ;
// 如果_owner不是当前线程
if (THREAD != _owner) {
// 当前线程是之前持有轻量级锁的线程。由轻量级锁膨胀后还没调用过enter方法,_owner会是指向Lock Record的指针。
if (THREAD->is_lock_owned((address) _owner)) {
assert (_recursions == 0, "invariant") ;
//在这时把owner修改为指向当前线程,应该是为了方便后面进行处理吧,因为只有这一种情况下是owner指向的不是线程。
_owner = THREAD ;
_recursions = 0 ;
} else {
// 异常情况:当前不是持有锁的线程
TEVENT (Exit - Throw IMSX) ;
assert(false, "Non-balanced monitor enter/exit!");
if (false) {
THROW(vmSymbols::java_lang_IllegalMonitorStateException());
}
return;
}
}
// 重入计数器还不为0,则计数器-1后返回,因为这表明这只是一次重量级锁的重入,只需要吧重入次数减一即可。
if (_recursions != 0) {
_recursions--; // this is simple recursive enter
TEVENT (Inflated exit - recursive) ;
return ;
}
// _Responsible设置为null,一直不知道这个SyncFlags是什么东西,也不知道代表什么意思,苦恼
if ((SyncFlags & 4) == 0) {
_Responsible = NULL ;
}
...
for (;;) {
assert (THREAD == _owner, "invariant") ;
// Knob_ExitPolicy默认为0
if (Knob_ExitPolicy == 0) {
// code 1:先释放锁,这时如果有其他线程进入同步块则能获得锁
OrderAccess::release_store_ptr (&_owner, NULL) ; // drop the lock
OrderAccess::storeload() ; // See if we need to wake a successor
// code 2:如果没有等待的线程(cxq和entryList都为空)或已经有假定继承人_succ不为空
// 那么表示不需要继续唤醒了,返回即可
if ((intptr_t(_EntryList)|intptr_t(_cxq)) == 0 || _succ != NULL) {
TEVENT (Inflated exit - simple egress) ;
return ;
}
TEVENT (Inflated exit - complex egress) ;
// code 3:要执行之后的操作需要重新获得锁,即设置_owner为当前线程
// 不满足上面的条件,表示需要挑一个线程唤醒,要操作_cxq 和 entryList,需要重新获取重量级锁
// 如果获取失败了,则表示此时重量级锁,已经被其他线程获取了,直接返回就行
// 如果获取成功了则下面需要按照不同的QMode进行处理
if (Atomic::cmpxchg_ptr (THREAD, &_owner, NULL) != NULL) {
return ;
}
TEVENT (Exit - Reacquired) ;
}else{
//此处代码忽略掉了
}
...
ObjectWaiter * w = NULL ;
// code 4:根据QMode的不同会有不同的唤醒策略,默认为0
int QMode = Knob_QMode ;
if (QMode == 2 && _cxq != NULL) {
// QMode == 2 : cxq中的线程有更高优先级,直接唤醒cxq的队首线程
w = _cxq ;
assert (w != NULL, "invariant") ;
assert (w->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
ExitEpilog (Self, w) ;
return ;
}
if (QMode == 3 && _cxq != NULL) {
// 将cxq中的元素插入到EntryList的末尾
w = _cxq ;
for (;;) {
assert (w != NULL, "Invariant") ;
ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w) ;
if (u == w) break ;
w = u ;
}
assert (w != NULL , "invariant") ;
ObjectWaiter * q = NULL ;
ObjectWaiter * p ;
for (p = w ; p != NULL ; p = p->_next) {
guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
p->TState = ObjectWaiter::TS_ENTER ;
p->_prev = q ;
q = p ;
}
// Append the RATs to the EntryList
// TODO: organize EntryList as a CDLL so we can locate the tail in constant-time.
ObjectWaiter * Tail ;
for (Tail = _EntryList ; Tail != NULL && Tail->_next != NULL ; Tail = Tail->_next) ;
if (Tail == NULL) {
_EntryList = w ;
} else {
Tail->_next = w ;
w->_prev = Tail ;
}
// Fall thru into code that tries to wake a successor from EntryList
}
if (QMode == 4 && _cxq != NULL) {
// 将cxq插入到EntryList的队首
w = _cxq ;
for (;;) {
assert (w != NULL, "Invariant") ;
ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w) ;
if (u == w) break ;
w = u ;
}
assert (w != NULL , "invariant") ;
ObjectWaiter * q = NULL ;
ObjectWaiter * p ;
for (p = w ; p != NULL ; p = p->_next) {
guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
p->TState = ObjectWaiter::TS_ENTER ;
p->_prev = q ;
q = p ;
}
// Prepend the RATs to the EntryList
if (_EntryList != NULL) {
q->_next = _EntryList ;
_EntryList->_prev = q ;
}
_EntryList = w ;
// Fall thru into code that tries to wake a successor from EntryList
}
w = _EntryList ;
if (w != NULL) {
// 如果EntryList不为空,则直接唤醒EntryList的队首元素
assert (w->TState == ObjectWaiter::TS_ENTER, "invariant") ;
ExitEpilog (Self, w) ;
return ;
}
// EntryList为null,则处理cxq中的元素
w = _cxq ;
if (w == NULL) continue ;
// 因为之后要将cxq的元素移动到EntryList,所以这里将cxq字段设置为null
for (;;) {
assert (w != NULL, "Invariant") ;
ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w) ;
if (u == w) break ;
w = u ;
}
TEVENT (Inflated exit - drain cxq into EntryList) ;
assert (w != NULL , "invariant") ;
assert (_EntryList == NULL , "invariant") ;
if (QMode == 1) {
// QMode == 1 : 将cxq中的元素转移到EntryList,并反转顺序
ObjectWaiter * s = NULL ;
ObjectWaiter * t = w ;
ObjectWaiter * u = NULL ;
while (t != NULL) {
guarantee (t->TState == ObjectWaiter::TS_CXQ, "invariant") ;
t->TState = ObjectWaiter::TS_ENTER ;
u = t->_next ;
t->_prev = u ;
t->_next = s ;
s = t;
t = u ;
}
_EntryList = s ;
assert (s != NULL, "invariant") ;
} else {
// QMode == 0 or QMode == 2‘
// 将cxq中的元素转移到EntryList
_EntryList = w ;
ObjectWaiter * q = NULL ;
ObjectWaiter * p ;
for (p = w ; p != NULL ; p = p->_next) {
guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
p->TState = ObjectWaiter::TS_ENTER ;
p->_prev = q ;
q = p ;
}
}
// _succ不为null,说明已经有个继承人了,所以不需要当前线程去唤醒,减少上下文切换的比率
if (_succ != NULL) continue;
w = _EntryList ;
// 唤醒EntryList第一个元素
if (w != NULL) {
guarantee (w->TState == ObjectWaiter::TS_ENTER, "invariant") ;
ExitEpilog (Self, w) ;
return ;
}
}
}上面的 exit 函数整体上分为如下几个部分:
- 首先判断owner是否是当前线程,因为只有获得当前锁的线程,才能执行exit。
- 对重入次数进行减1操作。
接下来是个无限循环,只有成功释放了锁,才会跳出循环。在循环中,主要做的事情是:
这里根据不同的退出策略执行了一段不同的逻辑,但是大致做的事情都差不多,这里我们只分析默认为0的情况。
首先释放掉当前线程对重量级锁的占用(设置owner为null),此时如果其他线程来抢占锁,是可以抢占成功的,有点类似ReenrantLock的非公平锁的意思。
然后判断了cxq队列和_EntryList是否都是空,或者是已经设置了假定继承人,如果是,就直接返回。因为没有线程需要唤醒,或者等待假定继承人去获得锁即可。
如果不满足上面条件,说明需要挑选一个线程来获取锁,那么这里因为需要操作
_cxq和_EntryList,所以需要重新CAS获取重量级锁。如果这里CAS获取失败,说明已经有其他线程获取到了锁,则直接返回即可
下面就需要根据策略从
_cxq和_EntryList中挑选一个线程唤醒了。
默认唤醒策略
默认的QMode为0,所以我们就先来分析这个策略的逻辑。
很奇怪,代码中,并没有单独判断QMode=0的这个种情况,所以我们需要把其他的逻辑去掉,剩下的就是QMode=0的逻辑了
void ObjectMonitor::exit(bool not_suspended, TRAPS) {
for (;;) {
...
ObjectWaiter * w = NULL;
int QMode = Knob_QMode;
if (QMode == 2 && _cxq != NULL){
...
}
if (QMode == 3 && _cxq != NULL){
...
}
if (QMode == 4 && _cxq != NULL){
...
}
w = _EntryList;
//优先从EntryList中唤醒线程
//判断entryList是否为空
if (w != NULL) {
//如果不为空,唤醒entryList的头节点
ExitEpilog(Self, w);
return;
}
//先把 cxq赋值给 w,然后清空cxq
w = _cxq;
// Drain _cxq into EntryList - bulk transfer.
// First, detach _cxq.
// The following loop is tantamount to: w = swap(&cxq, NULL)
for (;;) {
ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr(NULL, &_cxq, w);
if (u == w) break;
w = u;
}
if (QMode == 1) {
...
}else {
// QMode == 0 or QMode == 2
//将cxq中的元素转移到EntryList
//并将cxq转化为双向类别
_EntryList = w;
ObjectWaiter * q = NULL;
ObjectWaiter * p;
for (p = w; p != NULL; p = p->_next) {
p->TState = ObjectWaiter::TS_ENTER;
p->_prev = q;
q = p;
}
}
//唤醒entryList中的头部节点
w = _EntryList;
if (w != NULL) {
ExitEpilog(Self, w);
return;
}
}
}总结一下就是
- 在默认情况下,所有等待锁的线程,会先放到
_cxq队列中,后来的会放到_cxq的头部。 - 当之前持有锁的线程,执行完了同步代码,触发了锁退出逻辑。
- 在默认QMode=0的情况下下,其他模式我们先不分析了,首先会判断EntryList是否不为空,如果不为空,则唤醒EntryList的头节点的线程。
- 在首次重量级锁退出的时候,
EntryList肯定为空,则会继续向下走,会把_cxq中的节点,转移到_EntryList中,并把修改为双向节点。(可以知道,默认模式下,是在锁第一次释放的时候,把所有等待锁的节点移动到EntryList中) - 然后唤醒EntryList的头部节点。
根据这个逻辑,表现在Java程序中。有 T1,T2,T3,T4 四个线程按顺序去获得锁,那么最终获得锁的顺序是。
1. T1
2. T4
3. T3
4. T2
T4是最后进来的线程会放在在cxq队列的头部,在T1释放的时候,会转移到EntryList的头部,然后首先被唤醒。
我们来验证一下
package com.zhou.techstack.thread;
import java.util.concurrent.TimeUnit;
public class ThreadSyncOrder {
public static void main(String[] args) {
Object lock = new Object();
Thread t1 = new Thread(() -> {
System.out.println("Thread 1 start!!!!!!");
synchronized (lock) {
System.out.println("Thread 1 get lock!!!!!!");
sleepSeconds(5);
}
Thread t5 = new Thread(() -> {
System.out.println("Thread 5 start!!!!!!");
synchronized (lock) {
System.out.println("Thread 5 get lock!!!!!!");
}
});
t5.start();
});
Thread t2 = new Thread(() -> {
System.out.println("Thread 2 start!!!!!!");
synchronized (lock) {
System.out.println("Thread 2 get lock!!!!!!");
sleepSeconds(1);
}
});
Thread t3 = new Thread(() -> {
System.out.println("Thread 3 start!!!!!!");
synchronized (lock) {
System.out.println("Thread 3 get lock!!!!!!");
sleepSeconds(1);
}
});
Thread t4 = new Thread(() -> {
System.out.println("Thread 4 start!!!!!!");
synchronized (lock) {
System.out.println("Thread 4 get lock!!!!!!");
sleepSeconds(1);
}
});
t1.start();
sleepSeconds(1);
t2.start();
sleepSeconds(1);
t3.start();
sleepSeconds(1);
t4.start();
}
private static void sleepSeconds(int seconds) {
try {
TimeUnit.SECONDS.sleep(seconds);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}这个代码,我们在上面的逻辑基础上,有添加了一个逻辑,就是T1在释放锁之后,又创建了一个线程T5。 我们看一下执行结果
Thread 1 start!!!!!!
Thread 1 get lock!!!!!!
Thread 2 start!!!!!!
Thread 3 start!!!!!!
Thread 4 start!!!!!!
Thread 4 get lock!!!!!!
Thread 5 start!!!!!!
Thread 3 get lock!!!!!!
Thread 2 get lock!!!!!!
Thread 5 get lock!!!!!!- 首先
T1第一个启动,并且获得了锁,这个没有什么问题。 - 接着
T2,T3,T4相继启动,这时候我们根据上面的逻辑可以得知,这几个线程都会加入到_cxq中,并且顺序是T4->T3->T2。 - 接着
T1执行完毕,释放锁,这时候会把_cxq中的节点移动到EntryList中,并且唤醒头节点T4。然后T1紧接着创建T5,并启动,这时候T5,也会被加入到_cxq的头结点,只不过因为在释放的时候,_cxq中的节点已经移动到了EntryList,所以这时_cxq中只有T5一个节点。 - 接着
T4执行完毕,释放锁,这时因为EntryList不为空,所以唤醒此时EntryList的头结点T3 - 同样
T3执行完毕,释放锁,唤醒T2 T2执行完毕后,EntryList又变成空,所以会继续将_cxq中的节点移动到EntryList,然后唤醒头结点T5
其他唤醒策略
这里对于其他策略,我们就暂时不做分析了,但是大致的逻辑都是对_cxq和EntryList进行操作,调整他们的优先级,顺序,包括优先_cxq啊,反转_cxq啊等等。
有兴趣的同学也可以自己查看源码,或者查阅下面的参考文章。
wait、notify、natifyAll
wait
我们知道调用 lock.wait()之后,当前持有锁的线程,就会丢掉锁,并进入阻塞状态,等到调用 lock.notify()的时候才会被唤醒
下面我们来看源码来分析一下wait的实现原理。
int ObjectSynchronizer::wait(Handle obj, jlong millis, TRAPS) {
//如果使用偏向锁,首先撤销偏向。
//因为wait需要将线程放在ObjectMonitor的waitSet队列中,要wait必须要膨胀为重量级锁。
if (UseBiasedLocking) {
BiasedLocking::revoke_and_rebias(obj, false, THREAD);
assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now");
}
if (millis < 0) {
TEVENT(wait - throw IAX);
THROW_MSG_0(vmSymbols::java_lang_IllegalArgumentException(), "timeout value is negative");
}
//膨胀为重量级锁,如果已经是重量级锁, inflate方法会直接返回当前的ObjectMonitor
ObjectMonitor* monitor = ObjectSynchronizer::inflate(THREAD, obj());
DTRACE_MONITOR_WAIT_PROBE(monitor, obj(), THREAD, millis);
//调用ObjectMonitor的wait方法
monitor->wait(millis, true, THREAD);
// This dummy call is in place to get around dtrace bug 6254741. Once
// that's fixed we can uncomment the following line, remove the call
// and change this function back into a "void" func.
// DTRACE_MONITOR_PROBE(waited, monitor, obj(), THREAD);
return dtrace_waited_probe(monitor, obj, THREAD);
}通过这个方法我们可以知道,如果是在偏向模式和轻量级模式的同步代码中调用了wait()方法,那么也会导致锁升级到重量级模式。
然后就看ObjectMonitor的wait方法
void ObjectMonitor::wait(jlong millis, bool interruptible, TRAPS) {
Thread * const Self = THREAD;
assert(Self->is_Java_thread(), "Must be Java thread!");
JavaThread *jt = (JavaThread *)THREAD;
DeferredInitialize();
// Throw IMSX or IEX.
CHECK_OWNER();
EventJavaMonitorWait event;
// check for a pending interrupt
//检查是否被中断,中断了就就直接抛异常
if (interruptible && Thread::is_interrupted(Self, true) && !HAS_PENDING_EXCEPTION) {
// post monitor waited event. Note that this is past-tense, we are done waiting.
if (JvmtiExport::should_post_monitor_waited()) {
// Note: 'false' parameter is passed here because the
// wait was not timed out due to thread interrupt.
JvmtiExport::post_monitor_waited(jt, this, false);
// In this short circuit of the monitor wait protocol, the
// current thread never drops ownership of the monitor and
// never gets added to the wait queue so the current thread
// cannot be made the successor. This means that the
// JVMTI_EVENT_MONITOR_WAITED event handler cannot accidentally
// consume an unpark() meant for the ParkEvent associated with
// this ObjectMonitor.
}
if (event.should_commit()) {
post_monitor_wait_event(&event, 0, millis, false);
}
TEVENT(Wait - Throw IEX);
THROW(vmSymbols::java_lang_InterruptedException());
return;
}
TEVENT(Wait);
assert(Self->_Stalled == 0, "invariant");
Self->_Stalled = intptr_t(this);
//设置当前线程等到的OObjectMonitor为当前的ObjectMonitor
jt->set_current_waiting_monitor(this);
// create a node to be put into the queue
// Critically, after we reset() the event but prior to park(), we must check
// for a pending interrupt.
//将当前线程封装成ObjectWaiter
ObjectWaiter node(Self);
node.TState = ObjectWaiter::TS_WAIT;
Self->_ParkEvent->reset();
OrderAccess::fence(); // ST into Event; membar ; LD interrupted-flag
// Enter the waiting queue, which is a circular doubly linked list in this case
// but it could be a priority queue or any data structure.
// _WaitSetLock protects the wait queue. Normally the wait queue is accessed only
// by the the owner of the monitor *except* in the case where park()
// returns because of a timeout of interrupt. Contention is exceptionally rare
// so we use a simple spin-lock instead of a heavier-weight blocking lock.
//获取一个SpinLock
Thread::SpinAcquire(&_WaitSetLock, "WaitSet - add");
//将当前线程添加到WaitSet队列的最后面
AddWaiter(&node);
//释放SpinLock
Thread::SpinRelease(&_WaitSetLock);
if ((SyncFlags & 4) == 0) {
_Responsible = NULL;
}
intptr_t save = _recursions; // record the old recursion count
_waiters++; // increment the number of waiters
_recursions = 0; // set the recursion level to be 1
//释放锁对象
exit(true, Self); // exit the monitor
guarantee(_owner != Self, "invariant");
// The thread is on the WaitSet list - now park() it.
// On MP systems it's conceivable that a brief spin before we park
// could be profitable.
//
// TODO-FIXME: change the following logic to a loop of the form
// while (!timeout && !interrupted && _notified == 0) park()
// 下面进入阻塞状态
// 如果调用的wait(),则使用park进入没有超时时间的阻塞
// 如果调用的wait(time),是使用park(time)进入有超时时间的阻塞
// 进入阻塞之后,有三种会被唤醒的情况
// 1. 阻塞时间到了
// 2. 线程被中断了
// 3. 线程被notify唤醒
int ret = OS_OK;
int WasNotified = 0;
{ // State transition wrappers
OSThread* osthread = Self->osthread();
OSThreadWaitState osts(osthread, true);
{
ThreadBlockInVM tbivm(jt);
// Thread is in thread_blocked state and oop access is unsafe.
jt->set_suspend_equivalent();
if (interruptible && (Thread::is_interrupted(THREAD, false) || HAS_PENDING_EXCEPTION)) {
// Intentionally empty
} else if (node._notified == 0) {
// 根据入参 millis 判断是否有条件的挂起。这里挂起后,就不会继续往下执行了。
//除非timeout到时了,或者中断,或者notify/notifyAll
if (millis <= 0) {
Self->_ParkEvent->park();
} else {
ret = Self->_ParkEvent->park(millis);
}
}
// were we externally suspended while we were waiting?
if (ExitSuspendEquivalent (jt)) {
// TODO-FIXME: add -- if succ == Self then succ = null.
jt->java_suspend_self();
}
} // Exit thread safepoint: transition _thread_blocked -> _thread_in_vm
// Node may be on the WaitSet, the EntryList (or cxq), or in transition
// from the WaitSet to the EntryList.
// See if we need to remove Node from the WaitSet.
// We use double-checked locking to avoid grabbing _WaitSetLock
// if the thread is not on the wait queue.
//
// Note that we don't need a fence before the fetch of TState.
// In the worst case we'll fetch a old-stale value of TS_WAIT previously
// written by the is thread. (perhaps the fetch might even be satisfied
// by a look-aside into the processor's own store buffer, although given
// the length of the code path between the prior ST and this load that's
// highly unlikely). If the following LD fetches a stale TS_WAIT value
// then we'll acquire the lock and then re-fetch a fresh TState value.
// That is, we fail toward safety.
//执行到这儿,说明park的线程,已经被唤醒了,可能是timeout到时了,或者中断,或者notify/notifyAll
//首先要将其从WaitSet队列中移除。因为要操作waitSet,所以也要先获取锁
if (node.TState == ObjectWaiter::TS_WAIT) {
Thread::SpinAcquire(&_WaitSetLock, "WaitSet - unlink");
if (node.TState == ObjectWaiter::TS_WAIT) {
DequeueSpecificWaiter(&node); // unlink from WaitSet
assert(node._notified == 0, "invariant");
node.TState = ObjectWaiter::TS_RUN;
}
Thread::SpinRelease(&_WaitSetLock);
}
// The thread is now either on off-list (TS_RUN),
// on the EntryList (TS_ENTER), or on the cxq (TS_CXQ).
// The Node's TState variable is stable from the perspective of this thread.
// No other threads will asynchronously modify TState.
guarantee(node.TState != ObjectWaiter::TS_WAIT, "invariant");
OrderAccess::loadload();
if (_succ == Self) _succ = NULL;
//WasNotified用于判断,当前节点是否是通过notify唤醒的
WasNotified = node._notified;
// Reentry phase -- reacquire the monitor.
// re-enter contended monitor after object.wait().
// retain OBJECT_WAIT state until re-enter successfully completes
// Thread state is thread_in_vm and oop access is again safe,
// although the raw address of the object may have changed.
// (Don't cache naked oops over safepoints, of course).
// post monitor waited event. Note that this is past-tense, we are done waiting.
if (JvmtiExport::should_post_monitor_waited()) {
JvmtiExport::post_monitor_waited(jt, this, ret == OS_TIMEOUT);
if (node._notified != 0 && _succ == Self) {
// In this part of the monitor wait-notify-reenter protocol it
// is possible (and normal) for another thread to do a fastpath
// monitor enter-exit while this thread is still trying to get
// to the reenter portion of the protocol.
//
// The ObjectMonitor was notified and the current thread is
// the successor which also means that an unpark() has already
// been done. The JVMTI_EVENT_MONITOR_WAITED event handler can
// consume the unpark() that was done when the successor was
// set because the same ParkEvent is shared between Java
// monitors and JVM/TI RawMonitors (for now).
//
// We redo the unpark() to ensure forward progress, i.e., we
// don't want all pending threads hanging (parked) with none
// entering the unlocked monitor.
node._event->unpark();
}
}
if (event.should_commit()) {
post_monitor_wait_event(&event, node._notifier_tid, millis, ret == OS_TIMEOUT);
}
OrderAccess::fence();
assert(Self->_Stalled != 0, "invariant");
Self->_Stalled = 0;
assert(_owner != Self, "invariant");
//要继续执行,必须重新获取锁才可以,这里就是重新获取锁的逻辑。
//是经过了一定的阻塞时间,自己唤醒的,那么需要重新尝试获取锁,通过enter方法。
ObjectWaiter::TStates v = node.TState;
if (v == ObjectWaiter::TS_RUN) {
enter(Self);
} else {
guarantee(v == ObjectWaiter::TS_ENTER || v == ObjectWaiter::TS_CXQ, "invariant");
ReenterI(Self, &node);
node.wait_reenter_end(this);
}
// Self has reacquired the lock.
// Lifecycle - the node representing Self must not appear on any queues.
// Node is about to go out-of-scope, but even if it were immortal we wouldn't
// want residual elements associated with this thread left on any lists.
guarantee(node.TState == ObjectWaiter::TS_RUN, "invariant");
assert(_owner == Self, "invariant");
assert(_succ != Self, "invariant");
} // OSThreadWaitState()
//执行到这儿,说明线程被唤醒,并且重新获取了锁。
//设置当前线程wait的Monitor为NULL
jt->set_current_waiting_monitor(NULL);
guarantee(_recursions == 0, "invariant");
_recursions = save; // restore the old recursion count
_waiters--; // decrement the number of waiters
// Verify a few postconditions
assert(_owner == Self, "invariant");
assert(_succ != Self, "invariant");
assert(((oop)(object()))->mark() == markOopDesc::encode(this), "invariant");
if (SyncFlags & 32) {
OrderAccess::fence();
}
// check if the notification happened
//是否是notify唤醒的,如果不是,判断如果是中断,需要抛出中断异常
//判断是否是中断唤醒,如果是抛出中断异常
if (!WasNotified) {
// no, it could be timeout or Thread.interrupt() or both
// check for interrupt event, otherwise it is timeout
if (interruptible && Thread::is_interrupted(Self, true) && !HAS_PENDING_EXCEPTION) {
TEVENT(Wait - throw IEX from epilog);
THROW(vmSymbols::java_lang_InterruptedException());
}
}
}wait方法的主要逻辑是
- 将线程封装成ObjectWaiter。
- 添加到
WaitSet队列,WaitSet是一个双向循环队列,将其添加到了队列的末尾。(操作WaitSet的时候,都需要获得一个SpinLock) - 调用exit方法释放锁,exit是退出synchronized的逻辑,详细可看synchronized实现原理
- 将线程挂起,这里挂起根据入参millis进行了有条件的挂起(是否到时间自动唤醒)。挂起之后,线程就不再执行了,必须等待当前线程被唤醒才会继续执行。
- 线程被唤醒有三种情况:
- 到时间自动唤醒,
- 中断唤醒,
- notify/notifyAll唤醒( 这里准确来说是,notify之后,被移动到了
cxq队列,然后在exit的逻辑中获取到了锁,被唤醒)。
- 唤醒之后从WaitSet中移除。
- 判断是怎么唤醒的
- 自己到时间唤醒,调用
enter重新尝试获取锁 notify唤醒,- 中断唤醒,抛出中断异常。
- 自己到时间唤醒,调用
notify
根据java中关于notify的注释中说,notify会随机挑选一个处于阻塞状态的线程唤醒。那真的是随机吗? 下面我们根据看源码来分析一下。
void ObjectSynchronizer::notify(Handle obj, TRAPS) {
//如果使用偏向,先撤销偏向
if (UseBiasedLocking) {
BiasedLocking::revoke_and_rebias(obj, false, THREAD);
assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now");
}
//判断如果是轻量级锁,直接返回
markOop mark = obj->mark();
if (mark->has_locker() && THREAD->is_lock_owned((address)mark->locker())) {
return;
}
//获取重量级锁的ObjectMonitor并执行其notify方法
ObjectSynchronizer::inflate(THREAD, obj())->notify(THREAD);
}首先和wait一样,在调用notify后,也肯定会升级到重量级锁。
void ObjectMonitor::INotify(Thread * Self) {
//获取notify策略,默认为2
const int policy = Knob_MoveNotifyee;
Thread::SpinAcquire(&_WaitSetLock, "WaitSet - notify");
//取出 waitSet的头结点
ObjectWaiter * iterator = DequeueWaiter();
if (iterator != NULL) {
// Disposition - what might we do with iterator ?
// a. add it directly to the EntryList - either tail (policy == 1)
// or head (policy == 0).
// b. push it onto the front of the _cxq (policy == 2).
// For now we use (b).
if (policy != 4) {
iterator->TState = ObjectWaiter::TS_ENTER;
}
//设置线程是通过notify唤醒
iterator->_notified = 1;
iterator->_notifier_tid = Self->osthread()->thread_id();
ObjectWaiter * list = _EntryList;
//下面根据不同的策略进行唤醒。
if (policy == 0) { // prepend to EntryList
//添加到EntryList队列的队首
if (list == NULL) {
iterator->_next = iterator->_prev = NULL;
_EntryList = iterator;
} else {
list->_prev = iterator;
iterator->_next = list;
iterator->_prev = NULL;
_EntryList = iterator;
}
} else if (policy == 1) { // append to EntryList
//添加到EntryList队列的队尾
if (list == NULL) {
iterator->_next = iterator->_prev = NULL;
_EntryList = iterator;
} else {
// CONSIDER: finding the tail currently requires a linear-time walk of
// the EntryList. We can make tail access constant-time by converting to
// a CDLL instead of using our current DLL.
ObjectWaiter * tail;
for (tail = list; tail->_next != NULL; tail = tail->_next) /* empty */;
assert(tail != NULL && tail->_next == NULL, "invariant");
tail->_next = iterator;
iterator->_prev = tail;
iterator->_next = NULL;
}
} else if (policy == 2) { // prepend to cxq
//添加到CXQ队列的队首
if (list == NULL) {
iterator->_next = iterator->_prev = NULL;
_EntryList = iterator;
} else {
iterator->TState = ObjectWaiter::TS_CXQ;
for (;;) {
ObjectWaiter * front = _cxq;
iterator->_next = front;
if (Atomic::cmpxchg_ptr(iterator, &_cxq, front) == front) {
break;
}
}
}
} else if (policy == 3) { // append to cxq
//添加CXQ队列的队尾
iterator->TState = ObjectWaiter::TS_CXQ;
for (;;) {
ObjectWaiter * tail = _cxq;
if (tail == NULL) {
iterator->_next = NULL;
if (Atomic::cmpxchg_ptr(iterator, &_cxq, NULL) == NULL) {
break;
}
} else {
while (tail->_next != NULL) tail = tail->_next;
tail->_next = iterator;
iterator->_prev = tail;
iterator->_next = NULL;
break;
}
}
} else {
ParkEvent * ev = iterator->_event;
iterator->TState = ObjectWaiter::TS_RUN;
OrderAccess::fence();
ev->unpark();
}
// _WaitSetLock protects the wait queue, not the EntryList. We could
// move the add-to-EntryList operation, above, outside the critical section
// protected by _WaitSetLock. In practice that's not useful. With the
// exception of wait() timeouts and interrupts the monitor owner
// is the only thread that grabs _WaitSetLock. There's almost no contention
// on _WaitSetLock so it's not profitable to reduce the length of the
// critical section.
if (policy < 4) {
iterator->wait_reenter_begin(this);
}
}
Thread::SpinRelease(&_WaitSetLock);
}这里我们看到这个逻辑就比较简单了,就是从waitSet中取出头节点,然后根据策略,放到cxq或者entryList的不同位置。
根据不同的唤醒策略进行不同的操作:
- policy == 0 : 取出
WaitSet的队首元素,添加到EntryList队列的队首。 - policy == 1 : 取出
WaitSet的队首元素,添加到EntryList队列的队尾 - policy == 2 : 取出
WaitSet的队首元素,添加到CXQ队列的队首(默认策略) - policy == 3 : 取出
WaitSet的队首元素,添加CXQ队列的队尾
我们可以看到,notify方法并没有真正的去唤醒阻塞线程,只是把线程从waitSet移动到了cxq的头部,然后等待其他线程释放重量级锁之后,在exit方法中,真正的唤醒。
notifyAll
void ObjectMonitor::notifyAll(TRAPS) {
CHECK_OWNER();
if (_WaitSet == NULL) {
TEVENT(Empty-NotifyAll);
return;
}
DTRACE_MONITOR_PROBE(notifyAll, this, object(), THREAD);
int tally = 0;
while (_WaitSet != NULL) {
tally++;
INotify(THREAD);
}
OM_PERFDATA_OP(Notifications, inc(tally));
}上面看完notify,在看notifyAll就比较简单了。他是循环调用了notify方法,也就是把waitSet中的所有节点都添加到了cxq的头部。
cxq、entryList、waitSet总结
首先声明一下我们只分析默认策略下的情况。
- 所有获取重量级锁失败的线程,都会首先加入
cxq队列,并放到队列的头部 - 当之前持有锁的线程,执行完同步代码释放锁之后,会优先从
entryList队列选择下一个去竞争锁的线程(头结点) - 如果
entryList队列为空,则会把cxq队列拷贝到entryList中,并清空cxq队列,然后唤醒entryList的头结点 - 当持有锁的线程,调用了wait方法,当前线程会释放锁,然后把这个线程加入到waitSet的尾部。
- 当调用notify方法的时候,会取出
waitSet的头结点,然后放到cxq的头结点中(就像重新获取了一次) - 当阻塞一段时间自动唤醒后,会调用
enter方法重新获取锁,这时候如果获取失败,也会放到cxq的头结点中 - 当被
interrupt唤醒,会调用enter方法重新获取锁,这时候如果获取失败,也会放到cxq的头结点中。并且抛出中断异常
- 当调用notify方法的时候,会取出
- 我们看到线程wait之后,最终唤醒之后,都会加入到
cxq队列。
其他知识点(瞎写的)
安全点
安全点的官方定义是在程序执行期间的所有GC Root已知并且所有堆对象的内容一致的点。 在这个期间,所有的用户线程都会停顿,然后由vm线程来执行一些操作 比如我们已经知道 - 偏向锁的撤销, - 批量重偏向, - 批量撤销 - CMS中的某些步骤
当然这里只是简单的提一下。
jvm线程如何执行任务
在JVM中,每种需要VMThread执行的操作都被封装成了VM_Operation。然后具体的任务继承VM_Operation,然后把需要执行的逻辑放在doit方法中,比如批量向撤销操作就被封装成了VM_BulkRevokeBias。
在上面的revoke_and_bias代码中,执行安全点偏向撤销的代码:
VM_BulkRevokeBias bulk_revoke(&obj, (JavaThread*) THREAD,
(heuristics == HR_BULK_REBIAS),
attempt_rebias);
VMThread::execute(&bulk_revoke);
return bulk_revoke.status_code();他在doit方法中执行的逻辑是
virtual void doit() {
_status_code = bulk_revoke_or_rebias_at_safepoint((*_obj)(), _bulk_rebias, _attempt_rebias_of_object, _requesting_thread);
clean_up_cached_monitor_info();
}他的继承关系是
VM_BulkRevokeBias -> VM_RevokeBias -> VM_Operation
VMThread在执行的时候,会检查每个操作对象的evaluation_mode,来判断这个操作能不能并发的执行。
evaluation_mode这个方法是是定义在父类VM_Operation,默认是safepoint也就是需要所有线程都进入安全点,也就是需要stw。
子类可以选择重写这个方法。有下面几种选择
enum Mode {
_safepoint, // blocking, safepoint, vm_op C-heap allocated
_no_safepoint,// blocking, no safepoint, vm_op C-Heap allocated
_concurrent, // non-blocking,no safepoint, vm_op C-Heap allocated
_async_safepoint // non-blocking,safepoint, vm_op C-Heap allocated
};JVM中使用的CAS方法
在JVM代码中,实现CAS是借助于下面这个方法。
cmpxchg_ptr(intptr_t exchange_value,
volatile intptr_t* dest,
intptr_t compare_value)- cmpxchg_ptr这个方法的三个参数分别是
- 第一个 字段变化的值 exchange value
- 第二个 需要修改的字段地址 address
- 第三个 比较值, compare value,也就是只有当字段是这个值的时候,才能发生交换。
- 方法的返回值,如果交换成功,返回compare value
下面借助一个例子来说明这个方法的作用
//构建一个匿名偏向的对象头
markOop header = (markOop) ((uintptr_t) mark & ((uintptr_t)markOopDesc::biased_lock_mask_in_place |(uintptr_t)markOopDesc::age_mask_in_place |epoch_mask_in_place));
//构建一个偏向当前线程的对象头
markOop new_header = (markOop) ((uintptr_t) header | thread_ident);
//执行CAS操作
if (Atomic::cmpxchg_ptr((void*)new_header, lockee->mark_addr(), header) == header) {
//成功
}else{
//失败
}- 根据上面的代码,的意思就是,如果锁对象的对象头的值为匿名偏向状态,那么把锁对象的对象头修改为偏向当前线程的对象头