#JMM
什么是Memory Model
想要了解JMM,我们先来了解一下什么是内存模型,下面是JMM规范中对内存模型的描述。
A high level, informal overview of the memory model shows it to be a set of rules for when writes by one thread are visible to another thread.
内存模型是规定了一个线程的修改什么时候可能对其他线程可见的一组规则。
既然是规则,那么就会有强弱之分,所以就会多种不同的内存模型。
各种内存模型在设计的时候,需要考虑程序员在编程的时候的难易程度,还有程序的执行性能。
- 程序员对内存模型的使用。程序员希望内存模型易于理解,易于编程。程序员希望基于一个强内存模型来编写代码。
- 编译器和处理器对内存模型的实现。编译器和处理器希望内存模型对它们的束缚越少越好,这样它们就可以做尽可能多的优化来提高性能。编译器和处理器希望实现一个弱内存模型。
这些内存模型我们可以简单的分为
- 语言级内存模型,比如(JMM、C++11MM等等)
- 处理器内存模型,比如(TSO,PSO,RMO,PowerPC)
下面是语言内存模型,处理器内存模型和顺序一致性内存模型的强弱对比示意图:
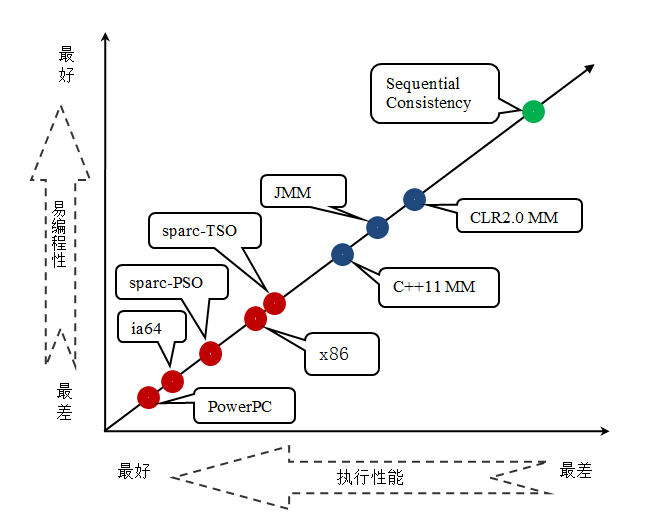
顺序一致性模型
顺序一致性内存模型是一个被计算机科学家理想化了的理论参考模型,它为程序员提供了极强的内存可见性保证。各种内存模型在设计的时候通常会把顺序一致性模型作为参考。然后在实现的时候会对顺序一致性模型做一些放松
因为如果完全按照顺序一致性模型来实现处理器和语言内存模型,那么很多的处理器和编译器优化都要被禁止,这对执行性能将会有很大的影响。
处理器内存模型
根据对不同类型读 / 写操作组合的执行顺序的放松,可以把常见处理器的内存模型划分为下面几种类型:
- 放松程序中写 - 读操作的顺序,由此产生了 total store ordering 内存模型(简称为 TSO)。
- 在前面 1 的基础上,继续放松程序中写 - 写操作的顺序,由此产生了 partial store order 内存模型(简称为 PSO)。
- 在前面 1 和 2 的基础上,继续放松程序中读 - 写和读 - 读操作的顺序,由此产生了 relaxed memory order 内存模型(简称为 RMO)和 PowerPC 内存模型。
注意,这里处理器对读 / 写操作的放松(重排序),是以两个操作之间不存在数据依赖性为前提的(因为处理器要遵守 as-if-serial 语义,处理器不会对存在数据依赖性的两个内存操作做重排序)
下面的表格展示了常见处理器内存模型的细节特征:
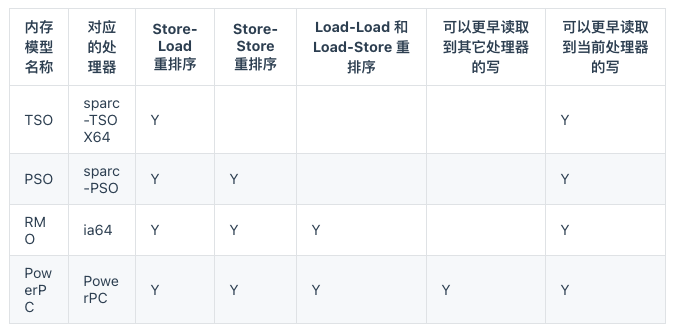
- 在这个表格中,我们可以看到所有处理器内存模型都允许写 - 读重排序,原因在第一章以说明过:它们都使用了写缓存区,写缓存区可能导致写 - 读操作重排序。同时,我们可以看到这些处理器内存模型都允许更早读到当前处理 器的写,原因同样是因为写缓存区:由于写缓存区仅对当前处理器可见,这个特性导致当前处理器可以比其他处理器先看到临时保存在自己的写缓存区中的写。
- 上面表格中的各种处理器内存模型,从上到下,模型由强变弱。越是追求性能的处理器,内存模型设计的会越弱。因为这些处理器希望内存模型对它们的束缚越少越好,这样它们就可以做尽可能多的优化来提高性能。
Java Memory Model
了解完内存模型,我们来说回JMM。
JMM是Java的设计者们权衡出来的一套规则。JMM的实现最终还是要借助于JVM编译器和各种处理器的内存模型。
如果一个处理器的内存模型强于JMM,那么对于JMM来说就不需要做任何额外的操作了,反之如果处理器的内存模型弱于JMM,那么JVM要想在这个处理器上依然能够实现JMM的规则,就需要一些
额外的操作,让处理器能够达到JMM的要求。这里的额外操作,就是指内存屏障。
JMM在不同处理器上的实现
由于常见的处理器内存模型比 JMM 要弱,java 编译器在生成字节码时,会在执行指令序列的适当位置插入内存屏障来限制处理器的重排序。 同时,由于各种处理器内存模型的强弱并不相同,为了在不同的处理器平台向程序员展示一个一致的内存模型, JMM在不同的处理器中需要插入的内存屏障的数量和种类也不相同。下图展示了 JMM 在不同处理器内存模型中需要插入的内存屏障的示意图:
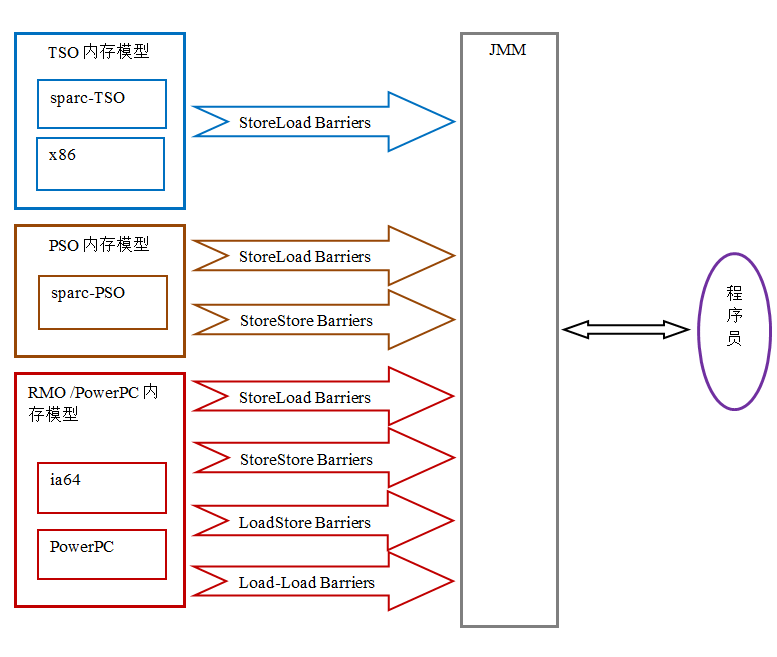
如上图所示,JMM 屏蔽了不同处理器内存模型的差异,它在不同的处理器平台之上为 java 程序员呈现了一个一致的内存模型。
Happens-Before
上面我们说到,内存模型,就是规定了一个线程中的修改什么时候可以对其他线程可见的规则。在JMM中使用happens-before这个概念来描述两个操作之间的可见性。
这两个操作既可以是在同一个线程,也可以是在不同的线程中。JMM中定义了8种关于happens-before的规则
- 单一线程原则:在一个线程内,在程序前面的操作先行发生(
happens-before)于后面的操作。 - 监视器锁定规则:一个 unlock 操作先行发生于后面对同一个锁的 lock 操作。
- volatile 变量规则:对一个 volatile 变量的写操作先行发生于(
happens-before)后面对这个变量的读操作。 - 线程启动规则:Thread 对象的 start() 方法调用先行发生(
happens-before)于此线程的每一个动作。 - 线程加入规则:Thread 对象的结束先行发生于 join() 方法返回。
- 线程中断规则:对线程 interrupt() 方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过 interrupted() 方法检测到是否有中断发生
- 对象终结规则:一个对象的初始化完成(构造函数执行结束)先行发生于它的 finalize() 方法的开始。
- 传递性:如果操作 A 先行发生于操作 B,操作 B 先行发生于操作 C,那么操作 A 先行发生于操作 C。
这种先行发生的需求,在我们的代码中也十分常见。在我们的逻辑中,经常会有这样的要求,先执行操作A,然后在执行操作B。也就是要求 操作A happens before 操作B
在单线程中,我们需要把操作A的代码写在操作B之前,就能实现。
多线程中,我们则需要对操作A和操作B,进行正确的同步操作。
Happens-Before和执行顺序
比如说现在有 操作1 happens before 操作2两个操作之间没有数据依赖。那么请问操作1一定在操作2之前被执行吗?
答案是不一定,这里唯一的例外就是在单线程情况下。
单线程
在单线程下,编译器和处理器遵循as-if-serial语义,保证不管怎么重排序也不会改变程序的执行结果。所以这里会对没有数据依赖的执行重排序。
所以这种情况下,虽然操作2可能会在操作1之前被执行,但是因为不影响程序结果,就像是按顺序执行一样,所以我们也认为这种是符合 操作1 happens before 操作2的。
多线程
在多线程中,如果两个线程中的操作1和操作2,满足操作1 happens before 操作2,那么我们就可以说,操作1一定在操作2之前被执行。
JMM中对long和double类型的读取
JVM规定 - 实现对普通long与double的读写不要求是原子的(但如果实现为原子操作也OK) - 实现对volatile long与volatile double的读写必须是原子的(没有选择余地)
所以是否是原子操作,需要看虚拟机的自己的实现。
目前情况是,是否为原子操作,和JVM所处的硬件平台,处理器位数都有关系。但是JVM提供了-XX:+AlwaysAtomicAccesses参数,来保证原子操作。
具体的测试可以查看这个文章 All Accesses Are Atomic
目前我们关注的,在目前intel平台的x64 hotspot jvm中,long 、double的访问是原子的.
总结
因为在不同的硬件生产商和不同的操作系统下,内存的访问逻辑有一定的差异,结果就是当你的代码在某个系统环境下运行良好,并且线程安全,但是换了个系统就出现各种问题。为了解决这个问题,Java 内存模型(JMM)的概念就被提出来了,来屏蔽掉各种硬件和操作系统的内存访问差异,以实现让 Java 程序在各种平台下都能达到一致的内存访问效果。
总的来说,就是JMM就是Java为开发者提供的,屏蔽了硬件差异,在多线程环境下保证线程间可见性的一套规则。
开发者按照这套规则开发代码逻辑,就能够在不同的硬件平台,获得一致的内存访问效果。
参考
JVM 基础 - Java 内存模型详解 Java 内存模型(Java Memory Model) 全面理解Java内存模型(JMM)及volatile关键字