字符编码
字符编码是我们在开发过程中无法逃避的问题,经常遇到各种各样的乱码。通常我们会在几个地方设置一下字符编码方式,然后乱码解决了,然后就会把字符编码放到一边,很少有机会或者会想到去专门系统的了解一下字符编码知识。
我之前也写过一些编码的文章,但是回过头在去看的时候,发现这也不对,那也不对,主要就是因为当时了解的比较片面。这次希望能够把常见的几种编码,和在编程中常见的编码问题搞清楚。
字符编码和字符集
- 字符集 字符集的意思就是所有字符的集合,并且每一个字符都有一个唯一的编号。
- 字符编码 字符编码就是把字符集内字符的编号转换成二进制数据的一种规则。
所以说字符集和字符编码并不是一个东西,字符编码需要依赖于字符集。但是大多数字符编码的名称就是它对应字符集的名称,比如 - ASCII字符集和ASCII字符编码 - GBK字符集和GBK字符编码
但是有一个例外就是基于Unicode字符集的UTF系列的字符编码,这个我们后面会重点说。 下面简单介绍几个我们比较熟悉的字符集,不会详细讨论设计细节,如果大家有需要可以去查看字符集的维基百科。后面后给出链接。
ASCII
ASCII可以认为是最早的字符集,它定义了128个字符,其中包括32个不可见字符(比如一些控制字符 换行,回车等),还有96个可见字符(大写小写字母,标点符号等)。
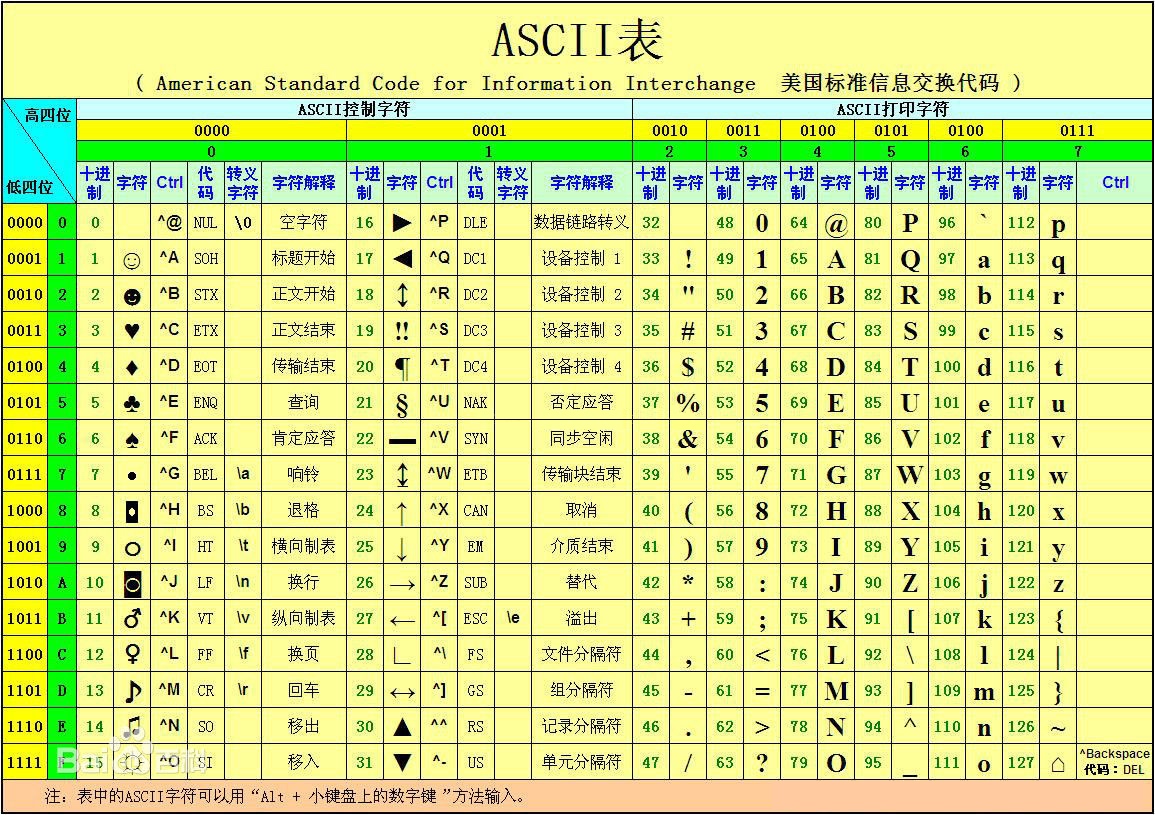 ASCII的字符编码也比较简单,就是用二进制来表示字符的序号,因为它一共只有128个,所以只需要用到一个字节的后7位。
ASCII的字符编码也比较简单,就是用二进制来表示字符的序号,因为它一共只有128个,所以只需要用到一个字节的后7位。
ISO 8859-1
ISO 8859-1 这个也是我们很熟悉的字符集,这个字符集是以ASCII为基础,并扩充了一些拉丁字母,也被叫做Latin-1字符集。
因为拉丁国家众多,有很多国家都对这个字符集进行了修改或者扩充。
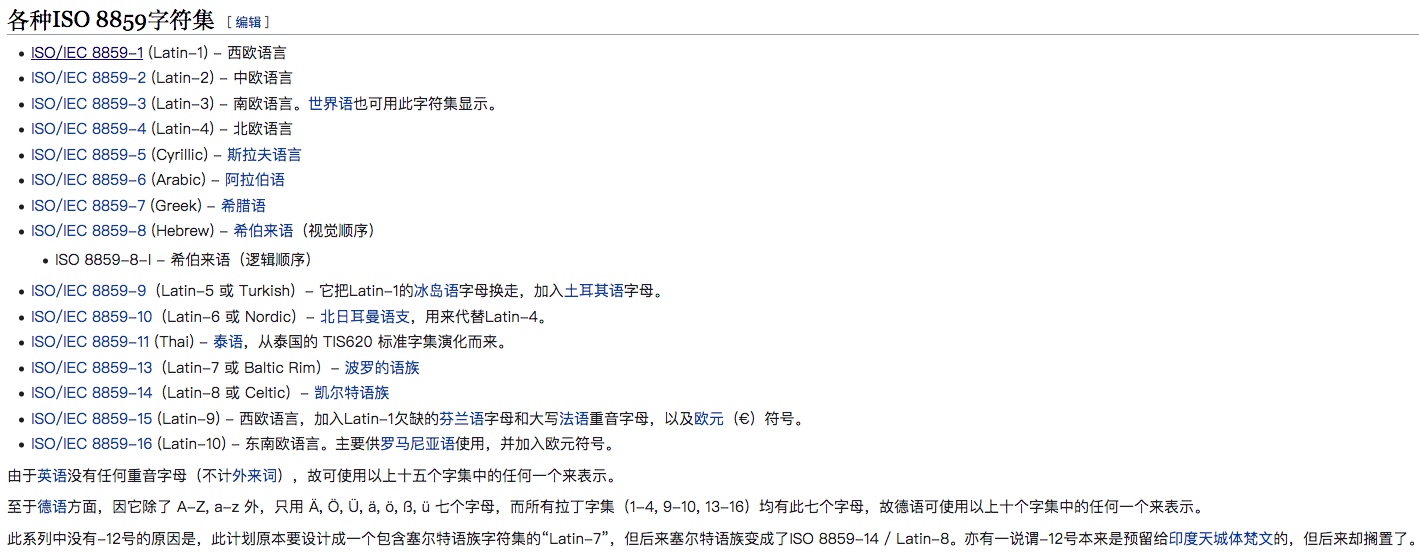 虽然有这么多的字符集,但是他们有一个共同点,他们都是采用的单字节的编码方式。
虽然有这么多的字符集,但是他们有一个共同点,他们都是采用的单字节的编码方式。
GBK
GBK的全称是汉字内码扩展规范。 其中 - GB是国标的首字母 - K 是扩展的首字母
GBK的其他信息,我们不做太多说明,有兴趣的可以去维基百科查看
GBK的编码方式
GBK分为单字节和双字节编码,单字节编码兼容ASCII字符集。
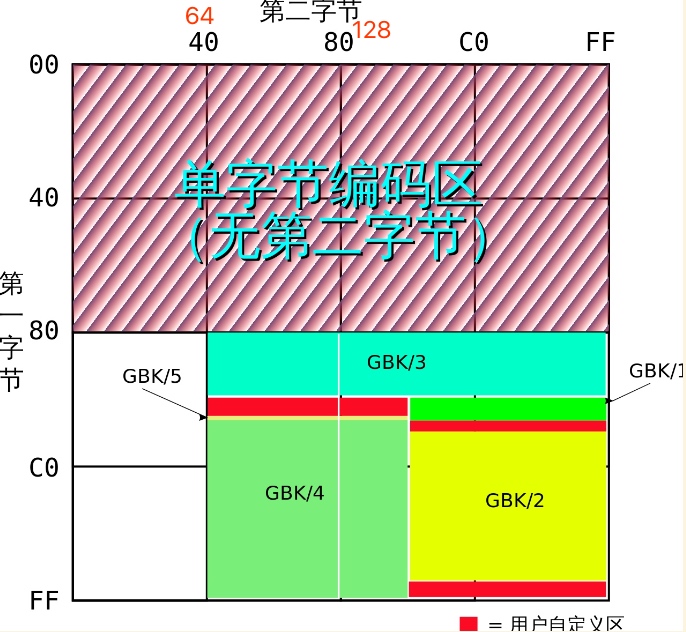
这张图片是GBK的编码分区图。
- 首字节 0-128(不包括128),都是单字节的编码区域
- 首字节 128-255,第二字节 0-64,这部分区域没有字符,如果出现在这个区域,会被解析为�
- 首字节 128-255,第二字节 64-255,这部分主要是中文符号。
根据上面的编码分区图,我们可以知道GBK是如何区分一个字节是是单字节编码,还是双字节编码的第一个字节,这个很重要,在下面乱码的解析中,我们会分析。 - 如果小于128,则表示是单字节编码 - 如果大于128,则表示是双字节编码
Unicode
因为世界上的国家有很多,使用的语言和文字也大相径庭,每个国家都有自己使用的字符集和编码,所以有必要使用一个统一的字符集来解决字符集分裂的问题。Unicode就是为了解决这个问题而诞生的。
Unicode中,是为每种语言都分配了一个区域,并且可以说是涵盖了世界上的所有的字符。
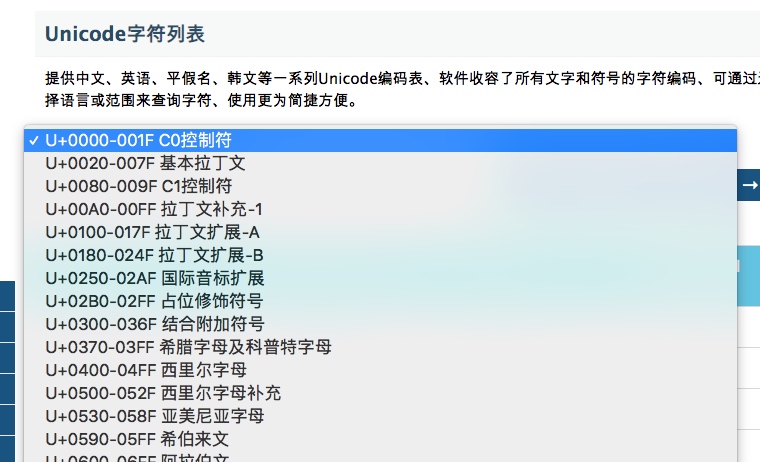
- 比如Unicode中的前128个字符和ASCII中的字符位置保持一致。
- 比如中文在Unicode的位置是 4E00-9FFF (19968-40959)
Unicode和UCS
UCS是Universal Multiple-Octet Coded Character Set的简称
Unicode和UCS的关系可以这么理解。 - 在历史中,有两个机构想要统一世界上的所有字符 - 国际标准化组织(ISO),设计出来的字符集就是UCS - 统一码联盟,设计出来的是Unicode - 后来,他们认识到,世界不需要两个不兼容的字符集,所以开始对这两个字符集进行合并。 - 从Unicode 2.0开始,Unicode采用了与UCS相同的字库和字码使两个字符集互相兼容。 - 但是各自依然保持独立。
UTF字符编码
需要明白的是,Unicode只是一个符号集,它只规定了符号的序号。字符集中的符号序号涵盖了1个字节,2个字节,3个字节,4个字节。 - 比如汉字的序号范围是 4E00到9FFF,在两字节的范围内。
那这里就有两个问题, - 第一个问题是,如何有3个字节计算机怎么知道这3个字节是表示一个符号,还是表示3个单字节符号呢? - 第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果 Unicode 统一规定,每个符号用3个或4个字节表示,那么每个英文字母前都必然有2到3个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
为了解决这两个问题,就出现了基于Unicode字符集的字符编码,UTF(Unicode/UCS Transformation Format)。 UTF编码又可以分为 - UTF-8 - 最小可以用一个字节来表示字符,以单字节(8位)为单位对Unicode进行编码 - UTF-16 - 最小需要用2个字节来表示,以2个字节(16位)为单位对Unicode进行编码 - UTF-32 - 最小需要4个字节来表示。以4个字节(32位)为单位对Unicode进行编码
UTF-8是使用最多的编码方式,下面我们会详细分析一下。 UTF-16和UTF-32我们使用较少,所以就不做分析了,有兴趣的同学可以自行了解一下。
冷知识:Java的String中保存字符的value字段,使用的是UTF-16编码来存储的

Unicode转换格式维基百科 UTF-8维基百科 UTF-16维基百科 UTF-32维基百科
UTF-8
UTF-8可以说是目前互联网中最常用的字符编码方式了。 截止到2019年11月, 在所有网页中,UTF-8编码应用率高达94.3%(其中一些仅是ASCII编码,因为它是UTF-8的子集),而在排名最高的1000个网页中占96%。
UTF-8编码规则
- 若果Unicode值小于128,则字节的第一位为0,后面的7位为这个符号的Unicode码。比如字母 “A” 的Unicode值是 65。这个规则只试用于 ASCII中定义的字符。所以也解决了上面中的因为字符空间占用问题。使用UTF-8表示英文字符同样只需要1个字节。
- 对于Unicode值大于128的字符(所有的非ASCII中定于的字符)。假定表示该自己在Unicode中的值,需要n(n>=1)个字节,则使用UTF-8编码是,第一个字节的前n+1位都设置为1,第n+2位设置为0,后面字节的前2位都设置为10。剩下没有设置的二进制位,全部为这个符号的Unicode值。
- 所以UTF-8表示ASCII字符 需要一个字节。
- 表示其他的非ASCII 字符,主要用改字符在Unicode中的位置转成2进制所占用的字节数+1个 字节。
- 也就是说,如果这个字符在Unicde中的位置,需要1个字节来表示,那么UTF-8需要2个字节来表示这个字符,以此类推。
总结一下规则就是;
所以这里总结一个UTF-8的规则就是,用第一个字节的前N位 有几个连续的1来表示,这个字符占了几个字节,然后后面紧连着几个字节如果以10开头则表示,这个字节适合第一个字节一起表示一个字符
- 如果一个字节是0开头,则表示是一个单字节字符
- 如果是11开头,则表示是一个双字节字符
- 如果是111开头,则表示是一个3字节字符,
- 比如汉字
中它的UTF-8编码是 1110 0100,10 111000,10 101101
- 比如汉字
- 如果是1111开头,则表示是一个4字节字符
UTF-8能够被广为使用的一个原因就是它兼容ASCII。 ASCII是UTF-8的一个子集。因为一个纯ASCII字符串也是一个合法的UTF-8字符串,所以现存的ASCII文本不需要转换。为传统的扩展ASCII字符集设计的软件通常可以不经修改或很少修改就能与UTF-8一起使用。 因为在Unicode出现之前,ASCII就是使用最广的语言。
UTF-8编码转换分析
我们还以汉字中为例,它的UTF-8编码是 11100100,10111000,10101101,我们下面来分析一下,如何计算出来的这个结果
- 我们先去网上查一下“中”对应的Unicode码:\u4e2d 对应的10进制 是 20013,也就是表示
中是Unicode中的第20013个字符。 - 对应的二进制是 :100111000101101(15位)为了方便转在前面加一个0,转为16位 01001110,00101101。
- 表示“中”在Unicode中的值,需要2个字节,所以参照上面规则,UTF-8表示这个“中”需要2+1 = 3 个字节
- 按照上面的规则 n =2 ,所以第一个字节的前2+1位设置为1 ,第4位设置为0,后面2个字节的前两位 都设置为 10
- 得到1110 **** , 10 ****** , 10 ******
- 剩下的位置填写
中的Unicode码的二进制 。剩下的位置共 4+6+6 = 16位,中的Unicode码的二进制也为16位,填入剩余的位置即可。 - 得到 1110 0100,10 111000,10 101101 。
代码中的乱码问题
乱码的出现
下面我们来聊一聊代码中经常遇到的乱码问题。 先说结论,乱码就是对字符编码(字符转成二进制)和解码(二进制转成字符)使用的编码不同。
举例说明一下:
计算机A 给 计算机B发送消息,内容为 “中国”。
- 计算机A中使用的编码是UTF-8,中国这两个字对应的UTF-8编码是E4B8AD E59BBD,对应的二进制是111001001011100010101101111001011001101110111101
- 计算机B,使用的编码是GBK,它收到网络中的数据,按照GBK的编码方式去解码。
- 然后结果必然是和期望的结果不同,解码的结果是涓浗;
上面的过程,我们可以用一段代码来表示
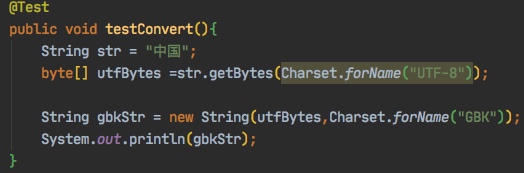
@Test
public void testConvert(){
String str = "中国";
byte[] utfBytes =str.getBytes(Charset.forName("UTF-8"));
String gbkStr = new String(utfBytes,Charset.forName("GBK"));
System.out.println(gbkStr);
}下面我们来分析一下这个乱码是如何产生的。
- 计算机B收到的二进制数据是
11100100 10111000 10101101 11100101 10011011 10111101
- B是使用GBK编码进行解码,所以我们按照上面的解码规则来解析
- 首先看第一个字节,大于128,所以是一个双字节编码,则读取前两个字节11100100 10111000
- 转换为16进制是E4B8,在GBK中对应的符号是涓
- 然后看第3个字节,同样大于128,所以也是双字节,然后读取第3和第4的字节10101101 11100101
- 转换为16进制是ADE5,查询GBK码表,显示这个位置并没有字符,所以显示为,但是其实这里是有一个特殊的填充字符的。和找不到字符的情况还是有区别的。下面我们会分析。
- 
- 然后查询第5个字节,同样大于128,所以也是双字节,然后读取第5和第6的字节`10011011 10111101`
- 转换为16进制是9BBD,查询GBK码表,对应的字符时`浗`。从乱码变回正常字符
通过上面的分析,我们知道我们接受到的字节数据是没有问题的,只要我们使用正确的编码对字节进行解码,就可以了。 > 但是一般在开发过程中,框架都帮我们完成了解码的工作,比如Tomcat。就是说我们获得就已经是乱码了。
所以说,如果我们能通过乱码,按照相同的编码方式来编码,就能拿到原始的字节数据,然后在使用正确的解码方式来解码,就能够得到正确的数据。
我们同样用程序来模拟一下上面的过程。(代码中使用的是Hutool的HexUtil工具类)
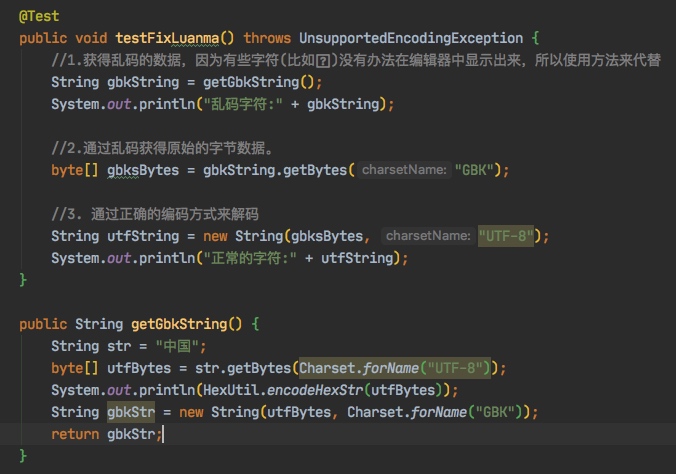
@Test
public void testFixLuanma() throws UnsupportedEncodingException {
//1.获得乱码的数据,因为有些字符(比如)没有办法在编辑器中显示出来,所以使用方法来代替
String gbkString = getGbkString();
System.out.println("乱码字符:" + gbkString);
//2.通过乱码获得原始的字节数据。
byte[] gbksBytes = gbkString.getBytes("GBK");
//3. 通过正确的编码方式来解码
String utfString = new String(gbksBytes, "UTF-8");
System.out.println("正常的字符:" + utfString);
}
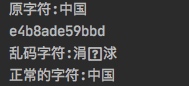
public String getGbkString() {
String str = "中国";
byte[] utfBytes = str.getBytes(Charset.forName("UTF-8"));
System.out.println(HexUtil.encodeHexStr(utfBytes));
String gbkStr = new String(utfBytes, Charset.forName("GBK"));
return gbkStr;
}一般情况下,我们使用获得乱码的编码方式,再对乱码进行编码,就能获得原始的字节数据。然后在使用正确的编码方式来解码,就能获得正确的字符。
例外情况
但是也有一种例外情况,如果你变成了乱码,然后在重新编码回来,是无法获得原始的字节数据的,也就没有办法再变成正确的字符了。
下面还是举例来说明一下
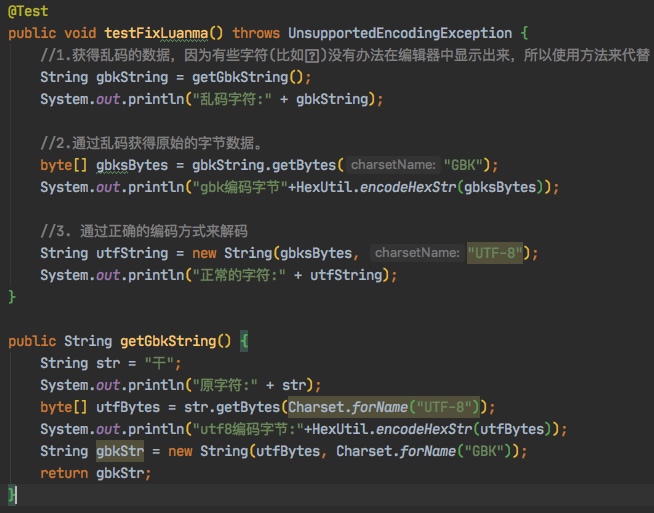
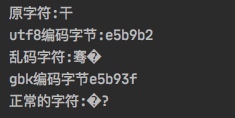
@Test
public void testFixLuanma() throws UnsupportedEncodingException {
//1.获得乱码的数据,因为有些字符(比如)没有办法在编辑器中显示出来,所以使用方法来代替
String gbkString = getGbkString();
System.out.println("乱码字符:" + gbkString);
//2.通过乱码获得原始的字节数据。
byte[] gbksBytes = gbkString.getBytes("GBK");
System.out.println("gbk编码字节"+HexUtil.encodeHexStr(gbksBytes));
//3. 通过正确的编码方式来解码
String utfString = new String(gbksBytes, "UTF-8");
System.out.println("正常的字符:" + utfString);
}
public String getGbkString() {
String str = "干";
System.out.println("原字符:" + str);
byte[] utfBytes = str.getBytes(Charset.forName("UTF-8"));
System.out.println("utf8编码字节:"+HexUtil.encodeHexStr(utfBytes));
String gbkStr = new String(utfBytes, Charset.forName("GBK"));
return gbkStr;
}我们发现,和上面一样的代码,对于不同的原字符,就出现了截然不同的结果。
我们来分析一下原因。
- 首先我们使用UTF-8对原字符
干编码,得到的结果是e5b9b2,转为二进制是11100101 10111001 10110010 - 使用GBK编码,对这段数据进行解码
- 首先读取第一个字节,大于128,认定是一个双字节字符,所以读取前两个字节
11100101 10111001,对应的16进制是e5b9。 - 查询GBK码表,对应的字符是
骞。 - 然后读取第三个字节,大于128,认定是一个双字节字符,但是这个只有一个字节,所以是有问题的,就被解析成
�。
- 首先读取第一个字节,大于128,认定是一个双字节字符,所以读取前两个字节
- 然后使用GBK编码对乱码重新编码,得到的字节数据是
e5b93f - 我们看到
�,这个字符被编码成了3f。 - 使用UTF8编码对
e5b93f解码,得到�?。
所以说,这里失败的原因是,当转换成GBK编码的时候,因为字节数为3个,所以最后1个字节被认为是错误的编码,被转成了通用错误字符�,导致再转成UTF-8的时候,无法还原成原始的字节数据。
总结一下
- GBK编码图中有一部分非法编码区,落在这个编码区的字符,或者不符合GBK编码规则的字符(比如大于128,但是只有一个字节),会被解析成
�。那么就会造成数据丢失,就无法转换成正确的数据了。 - 如果原始字节数据,是偶数字节,那么有很大可能都能被GBK正确解码,那么还是能够通过GBK编码获得原始数据的,那就能够重新获得正确的字符
- 有一种比较常见的情况是,发送方使用UTF-8格式的编码,接收方默认使用ISO-8859-1(Tomcat在不指定解码的时候,默认就是)。因为ISO-8859-1是单字节编码,所以虽然会是转换成乱码,但是每个字节都会有对应的字符,所以当再次使用ISO-8859-1编码,就不回发生数据丢失的情况,会原原本本的得到原始的字节数据,在按照UTF-8解码就可以了。
- 所以说如果一段字节数据,在使用某种编码解码A时,出现了不在该编码类型A的编码区中的数据。那么再次使用编码类型A编码时,就会出现数据丢失,导致无法还原会正确的字符。
GBK偶数字节乱码修复测试
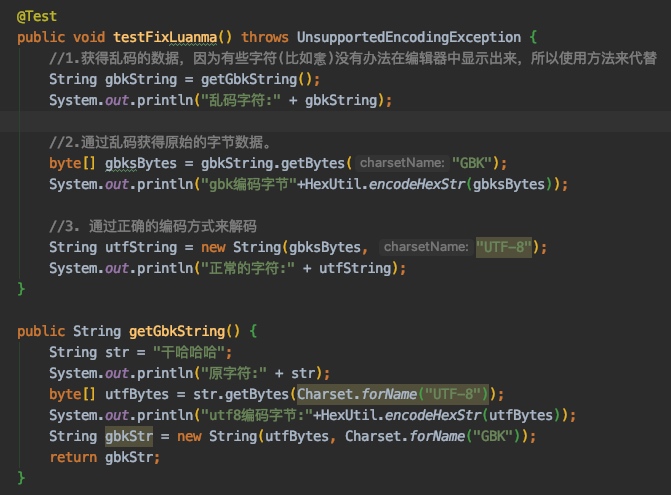
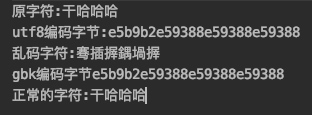
- 我们看到原始字符是
干哈哈哈,4个字符,使用UTF-8编码16进制是e5b9b2e59388e59388e59388,一共12字节。 - 使用GBK解码,正好2个自己对应一个字符,得到6个字符。
- 虽然文字看起来像乱码。
- 但是每个字节都有用到,没有发生数据丢失,这样我们再次使用gbk编码之后,就能重新得到
e5b9b2e59388e59388e59388,原始字节数据。 - 然后再次使用UTF-8解码就得到原始字符
干哈哈哈了。
ISO-8859-1乱码修复测试
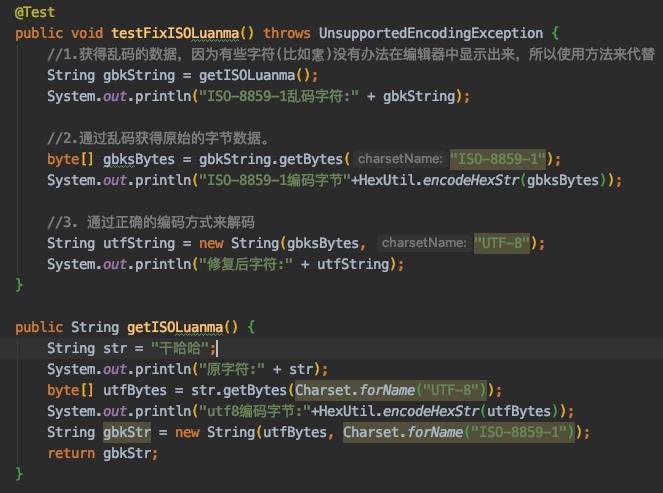
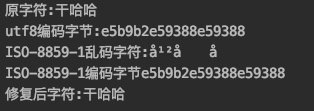
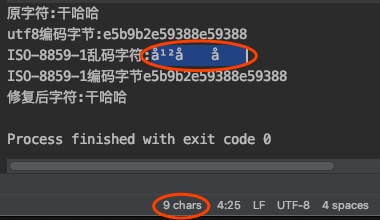
- 这次测试的原始字符换成了
干哈哈,UTF-8编码后16进制是e5b9b2e59388e593889个字节。 - 使用ISO-8859-1解码,得到了乱码,我们选中得到的字符,看到其实是9个字符
- 所以每个每个字节都对应了1个字符,没有数据丢失。
- 再使用ISO-8859-1对乱码编码,就重新得到了
e5b9b2e59388e59388原始字节数据。 - 然后再次使用UTF-8解码就得到原始字符
干哈哈了。